论文地址:Bottleneck Transformers for Visual Recognition
BoTNet是CV Transformer领域的创新之作,开启了一种CV Transformer backbone新范式。之前比较受认可的backbone网络ViT是在Transformer的结构中进行更适合图像的改进,而BoTNet则是在原始的CNN中进行Attention相关的改进。
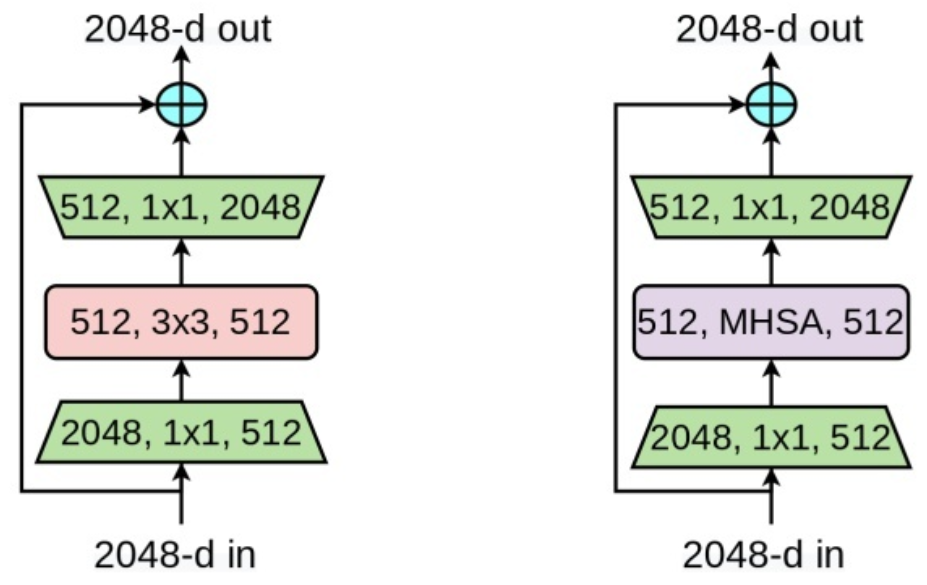
其主要思路非常简单,仅仅是使用改进后的Multi-Head Self Attention (MHSA)对ResNet最后三个bottleneck blocks中的卷积操作进行替换。如下图所示:
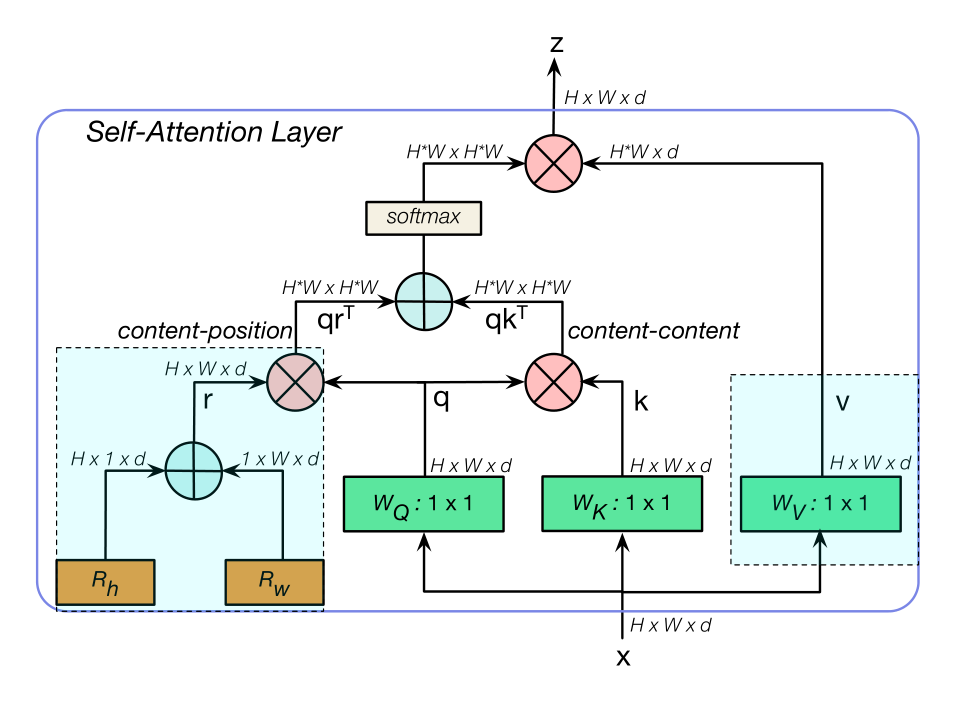
下图为BoT模块中使用的MHSA层。该层一共有四个head,在二维特征图上执行all2all attention,高度和宽度分别使用相对位置编码(relative position encodings)Rh和Rw来表示,使Rh和Rw中的每个元素分别进行求和得到对应于特征图中每个像素的内容位置(content-position)编码。剩下的和原始的NLP Multi-Head Self Attention差不多。