关于attention的详细介绍在Attention机制详解(一)——Seq2Seq中的Attention有详细介绍,在此不做多赘述。
添加了Attention的LSTM依然存在一些问题:
- 梯度消失,无法捕捉到长程的依赖关系;
- 运算量大,且无法并行。
以上问题在时序模型中普遍存在,于是一种能够拟合时序数据的非时序模型应运而生,那就是Transformer,而Transformer中的关键结构就是Self-attention。
Transformer的结构
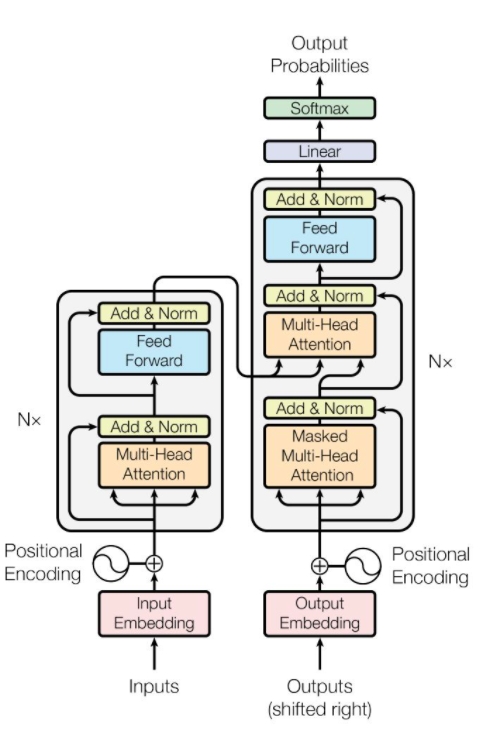
上图是一个Transformer的结构,其中Multi-Head Attention就是多个Self-Attention的结合。
Self-Attention
Self-Attention的作用
Transformer模型的左半部分称为Encoder,由多个Encoder模块组成,单个模块的结构可以看作下图。其输入为字符串中的多个字符经过Embedding后的相互无关的多个词向量,经过Self-Attention后得到一个新相互关联的向量,这就是Self-Attention的作用。
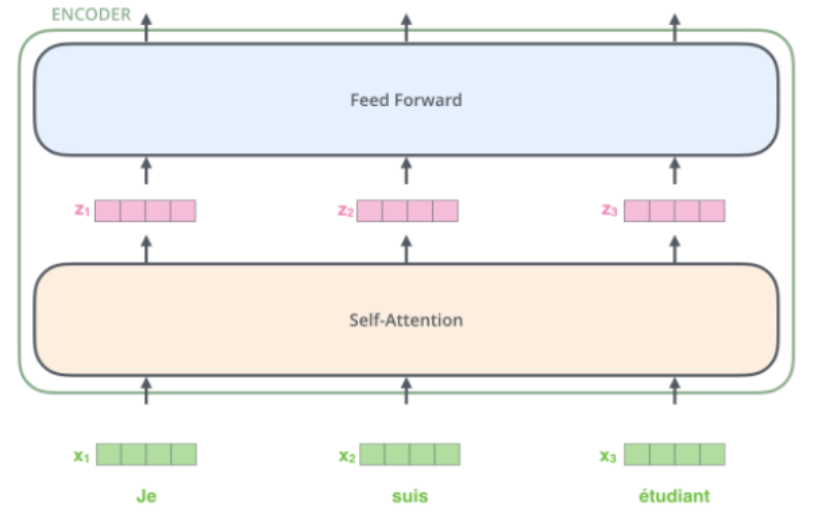
Self-Attention的原理
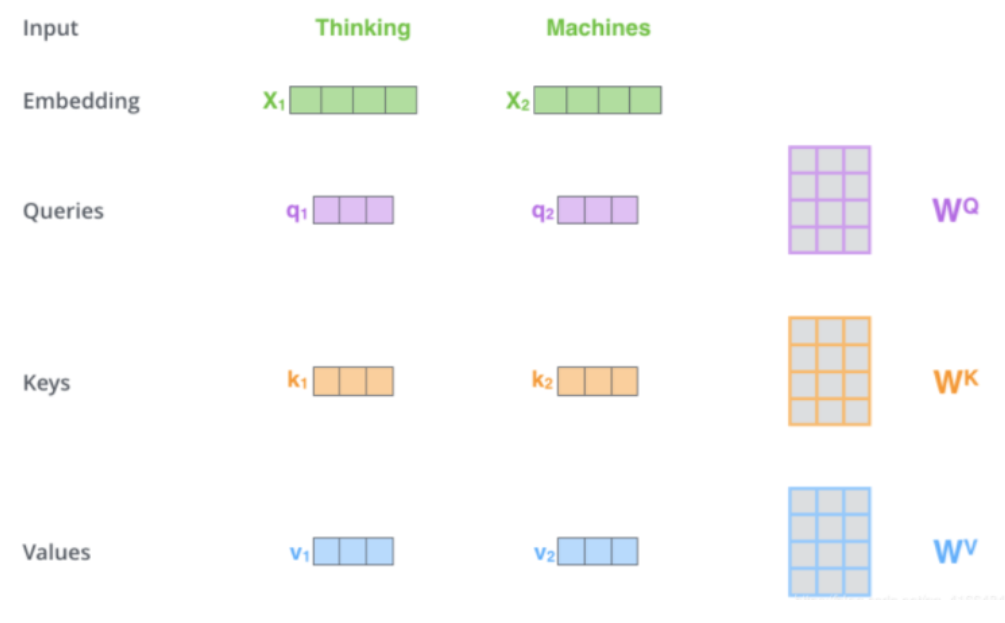
Self-Attention模块维护了三个可训练的矩阵,分别为$W_Q, W_K, W_V$,使用这三个矩阵与词向量相乘得到$q, k, v$三个向量。
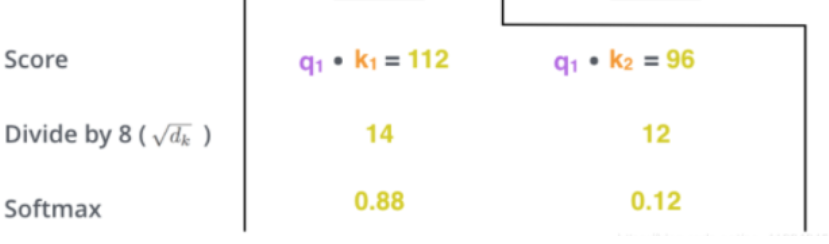
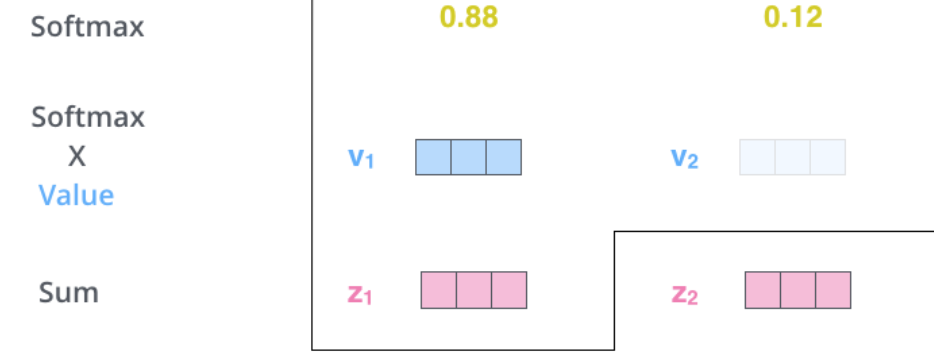
使$q_i$和$k_j$相乘得到attention score,该值表示翻译第i个词时,第j个词与其的相关度。显然,当前单词与其自身的attention score一般最大。然后除以8对该词进行缩放(这个除数由k向量的长度开根号得到,原论文中向量长度为64),使用softmax进行归一化。
最后使用softmax得到的结果对多个v向量进行加权求和,得到当前词的结果z,并将得到的所有z输入到下一个Encoder模块。
值得一提的是在Decoder中无法并行预测所有词,需要循环地一个个预测单词,因为要用上一个位置的输入当作attention的query。
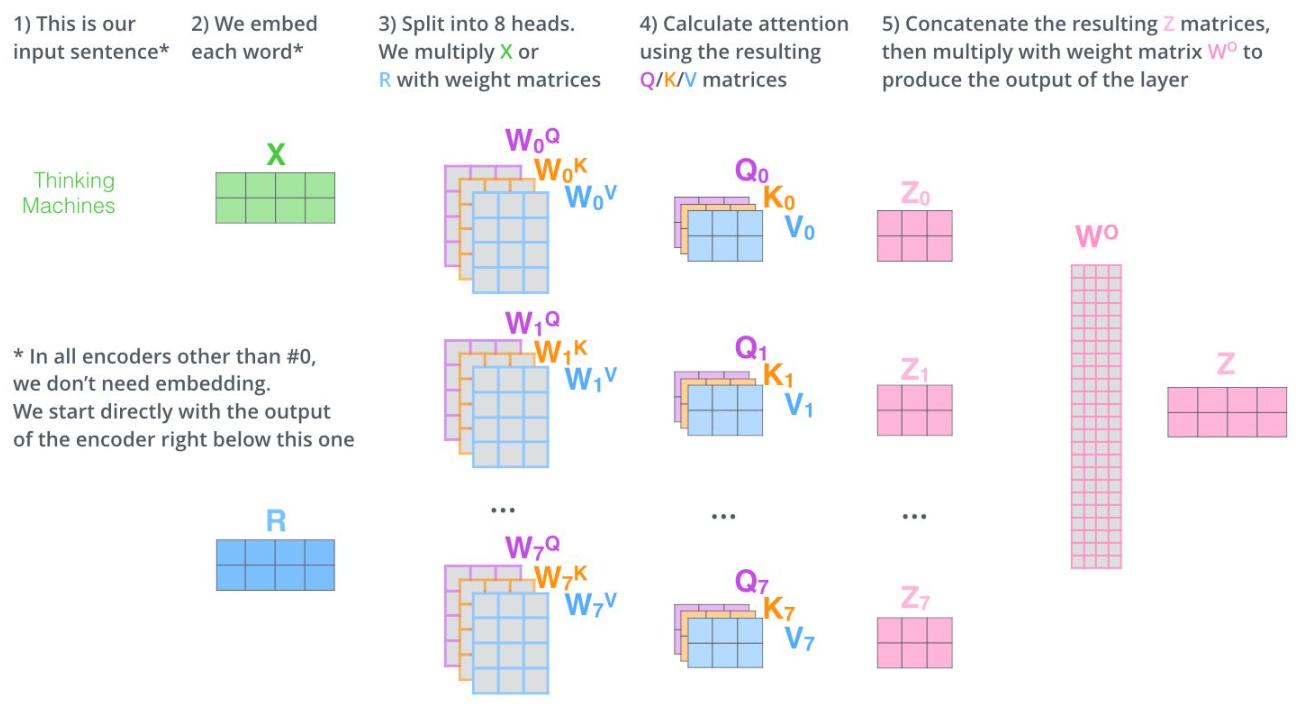
什么是Multi-head?
Multi-head就是我们可以有不同的Q,K,V表示的Self Attention,最后再将其结果结合起来,如下图所示:
Positional Encoding
#copy
由于Transformer中没有循环以及卷积结构,为了使模型能够利用序列的顺序,作者们需要插入一些关于tokens在序列中相对或绝对位置的信息。因此,作者们提出了位置编码(Positional Encoding)的概念。Positional Encoding和token embedding相加,作为encoder和decoder栈的底部输入。Positional Encoding和embedding具有同样的维度,因此这两者可以直接相加。
在位置编码的论文中,作者使用了不同频率的正弦函数和余弦函数作为位置编码用来表示每个词在句子中的位置,具体可参考博客。
参考文献
[1]Attention机制详解(二)——Self-Attention与Transformer
[2]transformer 模型(self-attention自注意力)
[3]对Transformer中的Positional Encoding一点解释和理解
[4]【NLP】Transformer模型原理详解