论文地址:Real-time Scene Text Detection with Differentiable Binarization
Github:https://github.com/MhLiao/DB(代码结构很复杂)
Structure
DB(Differentiable Binarization)是一个轻量级的、基于分割的场景文本检测(Scene Text Detection, STD)模型。该模型的原理简洁易懂,在本文中就简单介绍一下。
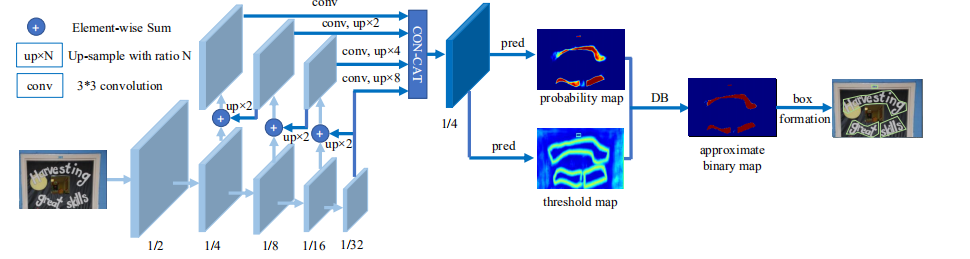
上图展示了DB的模型结构。前半部分是常见的32倍下采样+8倍上采样+特征融合,以及参考FPN采用了后四层反卷积的输出concat到一起进行预测。图中的pred是3×3卷积,输出两张map分别用来表示概率和阈值。使用阈值map对概率map进行二值化后,就将输出结果分为了前景(文本域)和背景。
这个自适应阈值能把分布比较密集的文本域给隔开,避免混淆成一个文本域。
值得一提的是阈值map只在训练的时候使用,在测试时仅使用固定阈值。估计在测试时使用DB并不能得到比较有效的提升,出于运算量的考虑决定去掉这部分。
Loss
损失函数分为三部分:概率图损失,阈值损失,二值图损失。其中概率图和二值图都使用交叉熵损失函数,而阈值损失使用的是L1损失函数。