论文地址:Towards Accurate Scene Text Recognition with Semantic Reasoning Networks
Github:https://github.com/chenjun2hao/SRN.pytorch (非官方)
Abstract
场景文本图像包含两个层次的内容:视觉纹理和语义信息。近年来,虽然已有的场景文本识别方法取得了很大的进展,但挖掘语义信息来辅助文本识别的研究却很少,只有类似RNN的结构被用来对语义信息进行隐式建模。然而,基于RNN的译码方法存在着时效性强、语义上下文单向串行传输等缺点,极大地限制了语义信息的利用和计算效率。为了缓解这些限制,我们提出了一种全新的端到端场景文本识别框架——语义推理网络(semantic reasoning network, SRN),其中引入了一个全局语义推理模块(GSRM),通过多路并行传输捕获全局语义。我们在常规文本、不规则文本和非拉丁文本等7个公共基准上都验证了该方法的有效性和鲁棒性。此外,相对于基于RNN的方法,SRN的速度有明显的优势,在实际应用中具有一定的价值。
1 Introduction
文本数据通常具有十分丰富的语义信息,这些信息已经被应用在许多计算机视觉的应用中,如自动驾驶、旅游翻译、产品检索等。场景文本识别是场景文本阅读系统的关键步骤。虽然Seq2Seq识别在过去的几十年里取得了一些显著的突破,但在现实场景中进行文本识别仍然是一个巨大的挑战,这归咎于场景文本在颜色、字体、空间布局甚至不可控的背景上都有很大的变化。
最近的大部分研究都试图从提取视觉特征的角度来提高场景文本识别的性能,如升级backbone,增加校正模块,改进注意机制等。然而对于人来说,场景文本的识别不仅依赖于视觉感知信息,还受到高层次文本语义语境理解的影响。如下图所示的一些例子,在只考虑视觉特征的情况下,很难区分这些图像中的每个字符,尤其是用红色虚线框突出的字符。相反,如果考虑到语义信息,人类很可能会根据单词的全部内容推断出正确的结果。
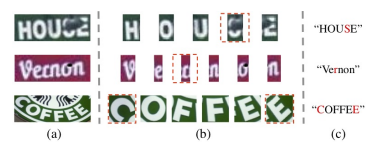
但主流的文本识别方法对于语义信息通常采用单向串行传输的方式(RNN),如下图(a)。这种方式有几个明显的缺点:第一,它的每个time step只能感知非常有限的语义语境;其次,当一个time step出现错误解码时,会对后面的time step产生错误累积;同时,序列模型难以并行计算,耗时且低效。
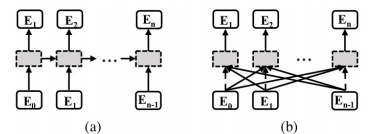
在本文中,我们引入了一种名为全局语义推理模块(GSRM)的子网络结构来解决这些问题。GSRM使用一种全新的多路并行传输方式将全局语义内容联系在一起。如图(b)所示,多路并行传输可以同时感知一个单词或文本行中所有字符的语义信息。单个字符的语义内容错误,对其他步骤的负面影响十分有限。
在此基础上,我们提出了一种基于语义推理网络的场景文本识别框架,该框架不仅集成了全局语义推理模块(GSRM),还集成了并行视觉注意模块(PVAM)和视觉语义融合解码器(VSFD)。PVAM的目的是在并行注意机制中提取每个time step的视觉特征,VSFD则用于融合视觉信息和语义信息。
这篇论文的贡献主要包含三部分:首先,我们提出了一个全局语义推理模块(GSRM)来处理全局语义信息。该方法比单向串行语义传输方法具有更好的鲁棒性和有效性。其次,提出了一种新的场景文本识别框架——语义推理网络(SRN),该框架有效地结合了视觉信息和语义信息。第三,SRN是可以端到端训练的,并在一些baseline中表现SOTA,其中包括常规文本、不规则文本和非拉丁长文本。
2 Related Work
不会吧不会吧,不会真有人看Related Work吧
3 Approach
SRN是一个端到端的可训练框架,它由四部分组成:backbone、并行视觉注意模块(PVAM)、全局语义推理模块(GSRM)、以及视觉语义融合解码器(VSFD)。对于一个给定的图像输入,首先使用backbone提取二维特征,然后使用PVAM生成$N$个对齐的一维特征$G$,其中每个特征对应于文本中的一个字符,并包含相对应的视觉信息。然后将这$N$个一维特征$G$输入到GSRM中以获取语义信息$S$。将对齐后的视觉特征$G$和语义信息$S$融合在一起,对$N$个字符进行预测。对于小于$N$的文本字符串使用’EOS’填充。SRN的详细结构如下图。
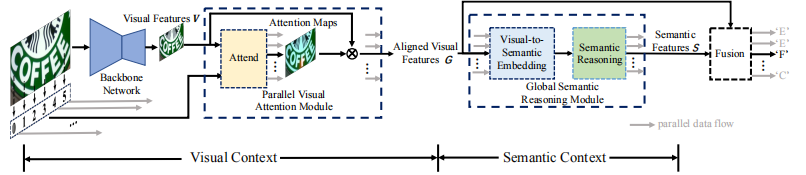
3.1 Backbone Network
在backbone中,我们使用FPN来融合ResNet50的stage-3, stage-4和stage-5层的特征。因此ResNet50+FPN最终输出特征图尺寸为输入图像的$1/8$,通道数为$512$。其灵感来源于non-local mechanisms,我们还采用transformer多头注意网络和一个前馈模块捕获全局空间依赖性。将二维特征图输入到两个堆叠transformer单元中,其中多头注意力的头数为$8$,前馈输出维度为$512$。至此,我们提取出了一个(大概是)$H×W×512$的特征。
总结:ResNet50 + FPN + 8 head transformer
3.2 Parallel Visual Attention Module
注意机制在序列识别中得到了广泛的应用。它可以看作是一种特征对齐的形式,将输入中的相关信息与相应的输出进行对齐。我们使用注意机制生成$N$个特征,每个特征对应文本中的一个字符。现有的注意力方法由于存在一些时间依赖项而导致效率低下。本文提出了一种新的注意方法——平行视觉注意(PVA),通过突破这些障碍来提高效率。
一般来说,注意机制可以描述如下:给定一个key-value集合和一个query, 计算query与所有keys的相似性。然后使values根据相似性来进行融合。在我们的研究中,key-value集合是输入的二维特征,现有的方法使用隐藏层$H{t-1}$作为query生成第$t$个特征。为了使计算并行,我们使用读取序号作为query,而不是依赖于时间的$H{t-1}$。文本中的第一个字符的读取序号为0,第二个字符的读取序号顺序为1,以此类推。我们的PVA可以总结为:
其中$W$均为可训练的权值。$O_t$是每个字符的读取顺序,$f_o$是embedding函数。
基于PVA的想法,我们设计了并行视觉注意模块(PVAM)用于对齐每个视觉特征和time step。对齐第$t$个time step和视觉特征的过程描述如下:
由于这个计算方法具有时间无关性,PVAM可以在所有time step上并行执行对齐操作。
如图所示,所得到的注意图能够正确地注意对应字符的视觉区域,验证了PVAM的有效性。

3.3 Global Semantic Reasoning Module
在本节中,我们提出了遵循多路并行传输思想的全局语义推理模块(GSRM),以克服单向语义上下文传递的缺点。首先我们回顾一下典型的类RNN结构的Bahdanau注意机制中需要最大化的概率公式。可以表示为:
其中$et$为第$t$个label $y_t$的词嵌入。在每个time step,类RNN的方法会参考先前的labels或者预测结果。由于$e{t-1}$、$H_{t-1}$等信息只能在time step中获取,使得这类方法的只能以序列的方式进行,限制了语义推理的能力,导致推理效率较低。
为了克服上述问题,我们使用一个时间无关的近似嵌入$e’$来代替真正的嵌入$e$。这种改进可以带来几个好处。1)首先,可以将上式中最后一步的$H_{t-1}$隐藏状态值去除,从而将串行推理过程升级为高效并行推理过程,因为所有的时间依赖项都已经被消除。2)第二,包括前后所有字符在内的全局语义信息都能用来推导当前时刻的语义状态。因此,我们将概率表达式改进如下:
其中$fr$表示用于建立全局语义和当前语义信息的函数。如果我们使$s_t=f_r(e_1…e{t-1}e_{t+1}…e_N)$,$s_t$表示第$t$个语义信息的特征,上式可以简化如下:
于此我们提出了GSRM。该结构分为两个关键部分:视觉语义嵌入模块(Visual-to-semantic embedding block)和语义推理模块(semantic reasoning block)。
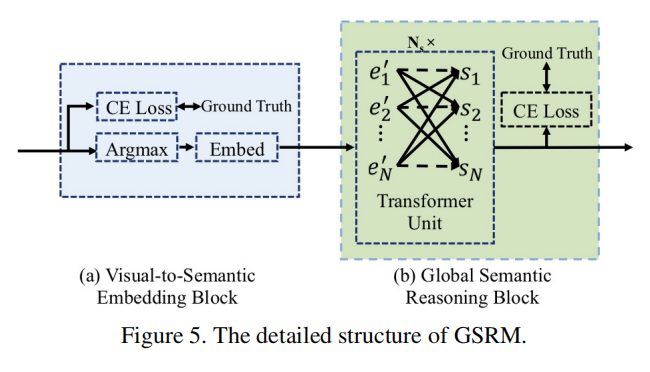
视觉语义嵌入模块用于生成$e’$,其输入特征已经经过PVAM对每个字符进行对齐。该视觉特征首先输入到一个全连接层和softmax层,并受到交叉熵损失监督。然后使用argmax选出可能性最大的字符进行embedding,得到$e’_t$。
语义推理模块用于全局语义推理,相当于上上条公式里的$f_r$。多个transformer单元使模型能够高效地感知全局上下文信息,词语的语义可以通过多个transformer单元隐式建模。最后通过该模块输出每一步的语义特征,受交叉熵损失监督。
通过交叉熵损失,从语义信息的角度对客观概率进行优化,也有助于减少收敛时间。值得注意的是,在GSRM中,全局语义是并行推理的,这使得SRN比传统的基于注意力的方法运行得更快,特别是在长文本的情况下。
3.4. Visual-Semantic Fusion Decoder
在场景文本识别的同时考虑视觉对齐特征和语义信息是非常重要的。然而视觉和语义属于不同的领域,在不同的情况下,它们在最终序列识别中的权重应该是不同的。受门控单元的启发,我们引入了一些可训练的权重来平衡VSFD中不同领域的特征贡献。其操作方式如下:
其中$W_z$为可训练的权值,$f_t$为第$t$次融合特征向量。