论文地址:Momentum Contrast for Unsupervised Visual Representation Learning
Abstract
我们提出了动量对比(Momentum Contrast, MoCo)的无监督视觉表示学习。从基于字典查找的对比学习(contrastive learning)的角度出发,我们构建了一个带有队列和移动平均编码器的动态字典:这使我们能够实时构建一个大型的、一致的字典,从而促进非监督对比学习。MoCo在ImageNet分类任务中表现优异。更重要的是,MoCo学到的表示可以很好地应用到下游任务(downstream task)中。MoCo可以在PASCAL VOC、COCO等7个数据集的检测/分割任务中超过了其监督学习的预训练模型。这表明,在许多视觉任务中,无监督和监督学习之间的差距已经很大程度上缩小了。
1 Introduction
无监督表示学习在NLP中的应用非常成功,如:GPT、BERT。但在CV领域,有监督的预训练仍占主导地位,而无监督的方法则普遍落后。原因可能是由于它们所属的信号空间不同。语言任务具有离散的信号空间(单词、子单词单元等)用于构建标记化词典( tokenized dictionaries),在此基础上进行无监督学习。相反,CV更加关注字典构建,因为原始信号处于连续的高维空间。
最近的一些研究提出了使用对比损失(contrastive loss)的无监督视觉表示学习,得出了令人激动的结果。这些方法可以看作是构建动态词典(dynamic dictionaries)。数据样本通过一个encoder提取特征后得到字典中的“密钥”(keys)。无监督学习训练encoder来执行字典查询过程:一个“查询”(query)通过encoder后,得到的输出应该与其匹配的key值相近,而与其他样本的key尽可能不同。学习目的为最小化contrastive loss。
从这个角度来看,我们认为应该在训练过程中逐步建立满足以下条件的词典:大型&一致。直观地说,一个更大的字典可以更好地对底层连续的、高维的视觉空间进行采样;而字典中的key应该用相同或类似的encoder表示,以便它们与query的比较是一致的。然而,使用现有的contrastive loss方法可能局限于这两个方面中的一个(稍后在下文中讨论)。
我们将动量对比(MoCo)作为一种构建大型且一致的字典的方式,用于非监督学习。我们将字典当作数据样本的队列:每当一个新的batch完成编码后进入队列,将最老的编码移出队列。队列将字典大小与batch大小解耦,如此一来就能独立建立字典(而不是依赖于batch大小),允许字典的大小比batch大很多。此外,由于字典的key来自前几个batch,为了保持一致性,我们提出了一种基于动量的encoder。
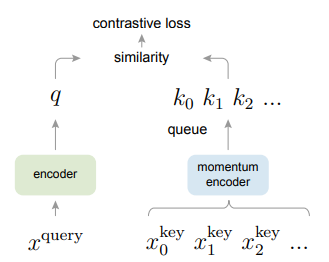
MoCo是一种建立动态对比学习词典的机制,可以与各种各样的前置任务(pretext task)一起使用。在本文中,我们使用一个简单的识别任务进行讲解:如果它们是同一图像(例如同一张图片的不同裁剪区域)的编码,那么query将给它们匹配同一个key。利用这个前置任务,MoCo在ImageNet数据集中展现了有力的结果。
2 Related Work
无监督/自监督学习方法一般包括两个方面:前置任务和损失函数。“前置”意味着正在解决的任务并不是我们最终要解决的任务,而是为了更好地学习数据的表示。损失函数通常可以独立于前置任务进行研究。MoCo专注于损失函数方面。接下来我们就这两个方面的相关研究进行讨论。
损失函数。损失函数是一种用于衡量模型的预测和固定目标值之间差距的方式。其中,对比损失(Contrastive losses)用于衡量两个样本在一个空间中的相似性。相比于将输入匹配到一个固定的目标,对比损失公式的目标可以在训练期间变化。对比学习是最近几篇关于无监督学习的研究的核心内容,我们将在后面对此进行阐述。
前置任务。前置任务的种类多种多样。例如修复遭到损坏的输入,包括:去噪自动编码器( denoising auto-encoders),上下文自动编码器(context autoencoders),或是用于着色的跨通道自动编码器(cross-channel auto-encoders);还有一些前置任务用于形成伪标签,例如,对图像进行转换(数据增强)、patch排序、视频目标的跟踪、分割、聚类。
3 Method
3.1 Contrastive Learning as Dictionary Look-up
对比学习(Contrastive learning)可以被看作是训练一个encoder进行字典查找任务。
假设已有一个已编码的查询$q$,和一组已编码的样本(即字典中的keys):${k0, k_1, k_2, …}$,$q$匹配到了字典中的一个key(表示为k)。$q$和其对 应的$k+$越相似且与其它的keys相差越大,对比损失函数值越小。一种和点积度量相似,被称为InfoNCE的对比损失函数在本文中被使用:
其中$\tau$是一个超参数,sum运算的对象是1个正样本和K个负样本。直观地说,这种损失是基于K+1类softmax分类器的对数损失,用于将$q$分类为$k_+$类中的其中一类。对比损失函数也可以基于其他形式,如margin-based losses和NCE loss的变体。
对比损失函数作为无监督的目标函数,用于训练encoder。一般来说,query表示为$q = f_q(x^q)$(同理,$k=f_k(x^k)$),其中$f_a$是一个encoder,$x^q$是一个query样本。它们的实例化,取决于特定的前置任务。输入$x^q$和$x^k$可以是图像、patch、或者是由一组patch组成的context。网络$f_q$和$f_k$可以是相同的、部分共享的、或是完全不同的。
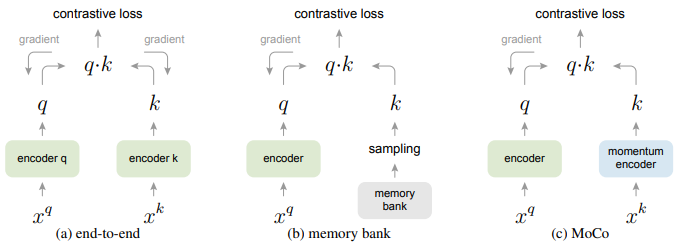
上图是三种对比损失机制的概念上的比较。这里我们会解释对于一对query和key,这三种机制在如何维护keys和如何更新keys encoder方面有所不同。(a):计算query和key的encoder通过反向传播端到端更新,这两个encoder可以是不同的。(b):密钥表示从存储库中采样。(c): MoCo通过动量更新encoder对新的keys进行动态编码。并维护keys的队列(图中没有说明)。
3.2 Momentum Contrast
从上面的观点来看,对比学习是一种在高维连续输入(如图像)上构建离散字典的方法。这个字典是动态的,因为键是随机采样的,而且key encoder在训练过程中会进化。我们的假设是,好的特征可以通过包含大量负样本的大字典来学习。而字典key的encoder则尽可能保持一致,不管它的发展。基于这个动机,我们现在的动量对比描述如下。
字典元素队列(Dictionary as a queue)。我们方法的核心是将字典作为一个数据样本队列来维护,这允许我们重用实时的keys。队列的引入将字典大小与batch大小解耦,所以字典大小可以比batch大小大得多。并且可以将字典的大小独立地设置为超参数。
当前batch被编入字典时,队列中最老的batch被删除。由于字典表示所有数据的抽样子集,因此维护字典的额外计算量是可控的。此外,删除最老的batch能够有效地保持一致性,因为其编码的keys是最过时的,与最新的keys最不一致。
动量更新(Momentum update)。使用队列可能会使字典变大,但它也使得通过反向传播(梯度应该传播到队列中的所有样本)来更新key encoder变得棘手。一个简单的解决方案是从query encoder$f_q$复制key encoder$f_k$,忽略这个梯度。但是这种解决方案在实验中产生的结果很差。我们假设这种故障是由于encoder的快速变化,降低了key的一致性造成的。于是我们提出了动量更新来解决这个问题。
形式上,我们将参数$f_k$、$f_q$指定为$\theta_k$、$\theta_q$,并通过如下公式更新$\theta_k$:
在这个公式中,$m\in [0,1)$为动量系数。只有$\theta_q$通过反向传播更新。动量更新公式使得$\theta_k$能够比$\theta_q$更加顺滑地进化。因此,虽然字典队列中不同batch的keys是由不同的encoder编码出来的,但编码器之间的差别很小。实验中通常使用相关性较大的动量(0.999)效果会比小动量(0.9)来带的效果好很多,这表明缓慢进化的key encoder是使得队列起作用的核心。
略过一些不是很重要的部分。
3.3 Pretext Task
对比学习可以驱动各种各样的前置任务。由于本文的重点不是设计一个新的前置任务,所以我们使用了一个简单的前置任务。
我们将来自同一张图像的query和key视为正样本对,否则视为负样本对。于是我们对同一幅图像进行随机数据增强生成两个新图像,形成正样本对。query和key分别由其各自的encoder进行编码,encoder可以是任意卷积神经网络。

上图中的算法用来给前置任务生成伪标签。
Technical details. 我们采用最后全局平均池化后面的全连接层的ResNet作为encoder,其具有固定维度的输出(128-D)。该输出向量使用L2-norm归一化,得到query或key的表示。动量公式中的温度$\tau$设为0.07。数据增强设置如下:随机resize后的图像中crop一个分辨率224×224的子图,然后经过随机颜色抖动(random color jittering)、随机的水平翻转(random horizontal flop)和随机的灰度转换(random grayscale conversion),这些都可以在PyTorch的torchvision包中导入使用。
Shuffling BN. 在实验中,我们发现使用BN对模型的训练有不利的影响。模型使用BN后会在前置任务中作弊,迅速找到低loss的解决方案。这可能是因为batch内的样本之间互相通信(由BN引起),泄露了信息。
于是我们提出了Shuffling BN来解决这个问题。由于使用多个GPU进行训练,每个GPU独立地对样本执行BN。对于key encoder,我们先对当前batch中的样本顺序进行洗牌,然后再将其分配给GPU进行编码,将输出的编码恢复原本的顺序;而query encoder的样本顺序不变。这确保用于计算query及positive key的batch统计信息来自两个不同的子集,有效地解决了作弊的问题,并允许训练受益于BN。
参考文献
[1]对比自监督学习
[2]CVPR 2020 | MoCo自监督学习或成为CV领域的启明灯
[3]何凯明组自监督方法MoCo开颅(1)
[4]Self-Supervised Learning 自监督学习中Pretext task的理解
[5]数据太少怎么办?试试自监督学习
[6]自监督学习的一些思考(入门向,推荐)