论文地址:Mask TextSpotter v3: Segmentation Proposal Network for Robust Scene Text Spotting
Github:https://github.com/MhLiao/MaskTextSpotterV3
Abstract
最近检测与识别相结合的场景文本识别端到端模型取得了很大进展。然而,目前的任意形状场景文本识别模型大多使用RPN来生成候选框,而RPN严重依赖于手工设计的轴对称矩形anchor。这使得处理高宽比或不规则形状的文本实例时存在困难,处理密集文本时单个候选框中容易包含多个相邻实例。为了解决这些问题,我们提出了Mask TextSpotter v3,一种端到端的场景文本识别器,其采用SPN(Segmentation Proposal Network)代替RPN。我们的SPN是anchor-free的,能够精确表示任意形状的候选区域。因此,我们的Mask TextSpotter v3可以处理极端宽高比或不规则形状的文本实例,而且它的识别精度不会受到附近文本或背景噪音的影响。
1 Introduction
在现实中阅读文本是一项非常重要的技术,有着广泛的应用,包括照片OCR,菜单阅读,地理定位等。系统针对该任务的设计一般包括文本检测和识别两个模块,其中文本检测的目标是对文本实例及其边界框进行定位,而文本识别的目标是将检测到的文本区域转换为一系列标签进行字符识别。场景文本识别/端到端识别是一个结合了这两种模块的任务,既需要检测又需要识别。
场景文本阅读的挑战主要在于场景文本实例的不同方位、宽高比和形状。因此,旋转鲁棒性,宽高比鲁棒性和形状鲁棒性在场景文本检测任务中是非常重要的。因为文本通常不会沿着图像的轴线对其,所以旋转鲁棒性非常重要。高宽比鲁棒性对于非拉丁文本尤其重要,因为这些文本通常表现为很长的文本行,而不是一个个单词。形状鲁棒性对于处理不规则形状的文本是必要的,不规则形状经常出现在logo中。
RPN的局限性主要表现在两个方面:(1)手工预先设计的锚点是使用轴对称的矩形来定义的,不易匹配高长比极端的文本实例。(2)文本实例密集时,生成矩形候选框可能包含多个相邻文本实例。如图a所示,由Mask TextSpotter v2产生的候选框相互重叠,其RoI特征包含多个相邻文本实例,导致检测和识别错误。

在本文中,我们提出了SPN,旨在解决RPN-based方法的局限性。SPN是anchor-free的,并给出了精确的多边形候选框,不用预先设计anchor。同时我们提出hard RoI masking应用到RoI特征中,可以抑制邻近的文本实例或背景噪声,从而充分利用该方法的精确性。我们的实验表明,Mask TextSpotter v3显著提高了对旋转、宽高比和形状的鲁棒性。在旋转的ICDAR 2013数据集上,图像以不同角度旋转,我们的方法在端到端检测和识别方面都超过了目前最先进的21.9%。在端到端识别任务中,我们的方法超出最先进方法5.9%。我们的方法还在具有极端高长宽比的文本行标记的MSRA-TD500数据集,以及包含许多低分辨率小文本实例的ICDAR 2015数据集上达到了最高水准。我们的贡献主要包括三方面:
- 我们提出的SPN能够精确表示任意形状的候选框。Anchor-free SPN克服了RPN在处理极端长宽比或不规则形状文本时的局限性,并提供了更精确的方案来提高识别的鲁棒性。据我们所知,它是首个用于端到端可训练文本定位的任意形状建议生成器。
- 我们提出了 hard RoI masking 将多边形候选框应用于RoI特征,有效地抑制背景噪声或相邻的文本实例。
- 我们提出的Mask TextSpotter v3显著提高了对旋转、宽高比和形状的鲁棒性,在几个具有挑战性的场景文本测试中取得了最先进的结果。
2 Methodology
Mask TextSpotter v3使用ResNet-50作为backbone,SPN生成候选框,一个Fast R-CNN模块微调候选框,一个文本实例分割模块用来精确检测,一个字符分割模块和一个空间注意力模块用来识别。Mask TextSpotter v3的pipeline如图所示。
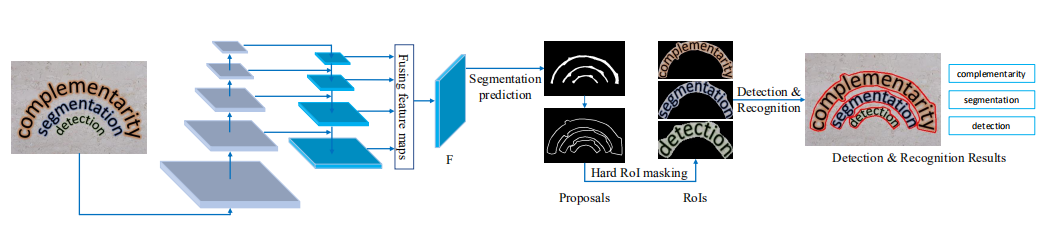
2.1 Segmentation proposal network
如上图所示,我们提出的SPN采用U-Net结构使其对尺度具有鲁棒性。和基于FPN多个阶段产生不同尺度的候选框的RPN不同,SPN从分割mask生成候选框,并且使用由多个感受野产生的特征图融合而成的特征图进行预测,该特征图长宽为输入图像的1/4。分割预测模块配置见文末补充。分割模型输出的掩码概率图尺寸和输入图像相同,通道数为1,取值范围为[0,1]。
Segmentation label generation. 为了分离邻近的文本实例,基于分割的场景文本检测器常用的方法是缩小文本区域。受DB模型的启发,我们采用Vatti裁剪算法,通过裁剪$d$个像素来缩小文本区域。偏移像素d可以确定为$d= A(1-r^2)/L$,其中$A$和$L$分别为文本域多边形的面积和周长,$r$为收缩比,通常设为0.4。生成label的例子如下图所示:

Proposal generation. 对于一个给定的值域在[0,1]之间的分割图,我们通过阈值对其进行二值化。对掩码$B$中连通的区域进行分组,这些连通区域可以被认为是缩小后的文本区域。因此,我们使用Vatti裁剪算法扩大它们$\hat d$个像素,其中$\hat d$计算为$\hat d=\hat A×\hat r / \hat L$。其中,$\hat A$和$\hat L$是缩小后文本区域的面积和周长。根据收缩比$r$的值,我们将$\hat r$设置为3.0。
如上所述,SPN产生的候选框可以精确地表示多边形文本区域。因此,SPN具有生成极端长宽比/密集/不规则形状的文本实例候选框的能力。
(概括:分割→缩小文本域→二值化→将连通的像素划分为一个文本域→恢复文本域大小)
2.2 Hard RoI masking
由于自定义RoI Align操作只支持轴对称的矩形bounding boxes,因此我们使用多边形候选框中的最小的、轴对称的矩形bounding boxes来生成RoI特征,以保持RoI Align操作。
Qin等人提出了RoI masking,将掩码概率图与RoI特征相乘,其中掩码概率图由Mask R-CNN检测模块生成。然而,掩码概率图可能不准确,因为其基于RPN的候选框进行预测,一个候选框中可能包含多个密集相邻的文本。而我们为候选框设计了精确的多边形表示。因此,我们提出了 hard RoI masking 直接将这些候选框应用到RoI特征上。
Hard RoI masking将二值多边形掩码与RoI特征相乘,以抑制背景噪声或邻近文本实例,大大降低了检测和识别模块的执行难度和出错概率。
2.3 Detection and recognition
我们遵循Mask TextSpotter v2的文本检测和识别模块的主要设计,原因如下:(1)Mask TextSpotter v2是目前最先进的、具有竞争力的检测和识别模块。(2)由于Mask TextSpotter v2是基于RPN的场景文本检测中一种具有代表性的方法,我们可以控制变量,来验证我们所提出的SPN的有效性和鲁棒性。
检测时,将Hard RoI masking生成的masked RoI特征输入到Fast R-CNN模块以进一步细化定位,并使用文本实例分割模块进行精确分割。采用字符分割模块和空间注意力模块进行识别。
2.4 Optimization
损失函数$L$定义如下:
$L{rcnn}$和$ L{mask}$分别在Fast R-CNN和Mask TextSpotter v2中有过明确定义。$L_{mask}$由文本分割损失、字符分割损失、空间注意力解码器损失组成。$L_s$表示SPN的损失。根据Mask TextSpotter v2,我们将$\alpha_1$和$\alpha_2$设为1.0。
我们采用dice loss计算SPN的损失。设$S$和$G$分别为分割结果mask和目标mask,则$L_s$可由如下公式计算:
(大概意思就是两个mask重合率越高,损失越小)