最近get到一个project做停车位检测,参考了几篇论文之后决定用关键点检测的方法,于是顺便读了如下几篇关键点检测相关的神经网络论文。
Hourglass
论文链接:Stacked Hourglass Networks for Human Pose Estimation
Stacked Hourglass Neworks(以下简称Hourglass)由多个Hourglass模块堆叠而成,其模块对特征图进行下采样后,将特征图上采样到原来的大小,形似沙漏,故名Hourglass。
Hourglass原本是用于做人体姿态估计(Human pose estimation),其中比较关键的一步就是检测人体上的关键点。人体不同的部位特征不同,所需要的特征图大小也不一样。Hourglass网络能够处理各种尺寸的人体特征,以此来捕捉人体各部位之间的空间关系。
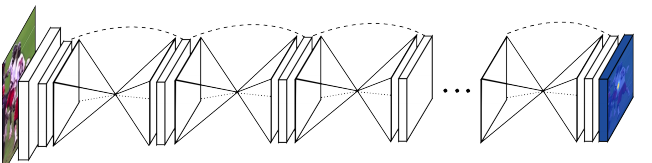
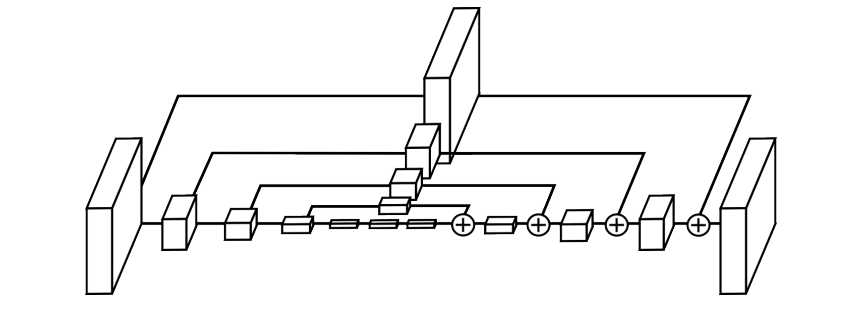
每个Hourglass模块采用encoder-decoder结构,对输入图下采样提取特征后进行上采样,输出原图大小的heatmap作为关键点的标记。encoder和decoder之间使用残差结构融合前后特征。

该网络的思想和结构后被其它检测网络广泛采用。
CornerNet
论文链接:CornerNet: Detecting Objects as Paired Keypoints
代码链接:https://github.com/umich-vl/CornerNet
CornerNet是一个通过检测对角来进行目标检测的网络。主要原理是采用Hourglass作为基本结构,输出检测框对角的Heatmap。
这个设计真的很反人类反人工智能,因为对角上应该是没有什么特征的。但是该网络的设计思想非常有意思,给后来的Anchor Free类型的目标检测网络提供了思路。
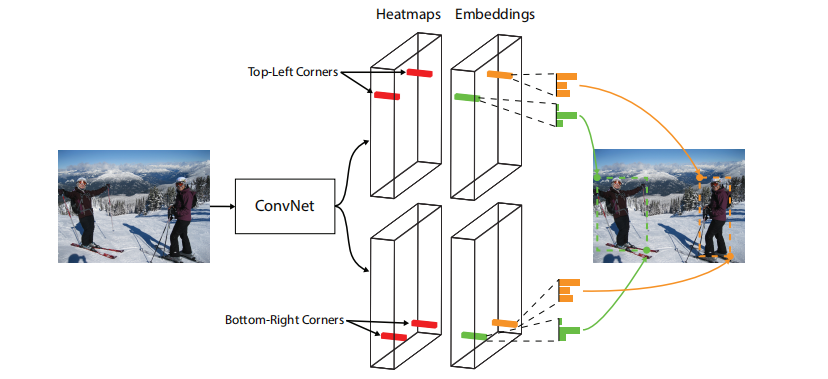
CornerNet的整体结构如下图所示,其骨干部分使用Hourglass,输出部分有两个分支模块,分别表示左上角点预测分支和右下角点预测分支,每个分支模块包含一个corner pooling层和3个输出:heatmaps、embeddings和offsets。
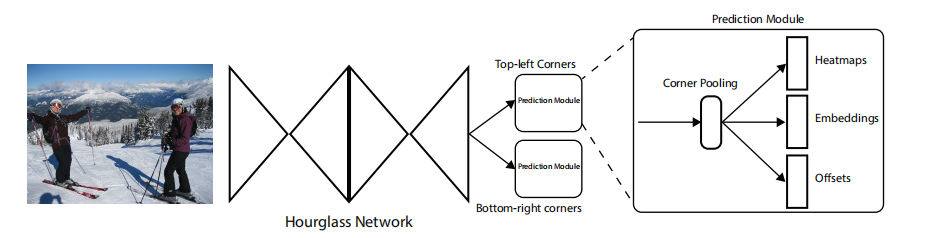
1 输出端
Heatmaps对角点的位置进行预测,即对每个像素点进行角点概率预测,最有可能是角点的位置输出值越高。其gt是以角点位置为中心的范围为n×n的高斯核;
Offset输出取整计算时丢失的精度信息,看起来用处可能没那么直观,但通常能有效提高精度上限;

Embedding用来对左上角点和右下角点进行匹配。其对每个角点输出一个vector,当两个角点的vector距离较小时,则认为这两点为成对点(这个和人脸匹配有点像)。这部分由两个损失函数实现,第一部分用来缩小成对点向量的距离,第二部分用来放大非成对点向量之间的距离。
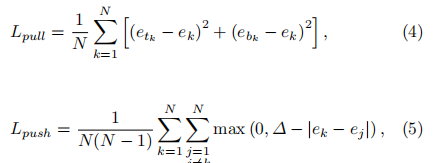
2 Corner Pooling
因为CornerNet是预测左上角和右下角两个角点,但是这两个角点在不同目标上没有相同规律可循,如果采用普通池化操作,那么在训练预测角点支路时会比较困难。考虑到对于每一个左上角点,其所有的特征都在其右下方。因此如果左上角角点经过池化操作后能有其右下方的信息,那么就有利于该点的预测。右下角点同理。
Corner Pooling便是一种对某个像素的右下方(或左上方)的所有像素进行池化的操作。
CenterNet
论文地址:Objects as Points
Github:https://github.com/xingyizhou/CenterNet
CenterNet有两篇发布时间十分接近的两篇论文,这里我们讲其中开源项目Star比较多、受认可度比较高的Objects as Points。
单从网络的结构和损失函数来看,这个模型是非常符合当代神经网络设计思想的模型:设定简约,输入输出端到端,且能够适应多种任务。堪称神经网络中的艺术品。
1 Abstract
在普通的目标检测任务中,CenterNet的思想和CornerNet十分接近。只不过CornerNet输出的是边框两个角点的坐标,而CenterNet输出的是中心点的坐标及其到边框的距离。
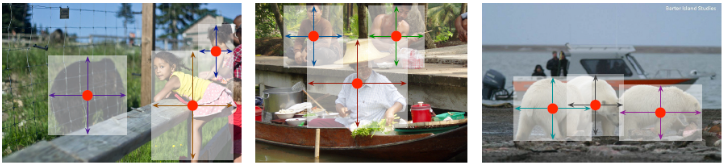
CenterNet还能用于3D目标检测(3D object detection)和多人人体姿态估计(multi-person human pose estimation)。在3D目标检测任务中,网络预测目标中心点的位置和深度、3D检测框的长宽以及目标的方向;在多人姿态估计任务中,网络预测中心点的位置以及各个关键的对中心点的偏置(offset)。
2 Related work
CenterNet的改变和优势:
在目标检测任务中,相比于RCNN系列网络,没有使用RPN、Anchor、NMS技术,没有使用阈值做前后景分类。仅仅提取特征图上的局部峰值点作为中心;
在通过关键点做目标检测的任务中,相比于CornerNet等网络,不需要对关键点进行配对操作;
在单目3D目标检测任务中,相比于Deep3Dbox等网络,同样更加简洁快速。

3 Method
这部分和CornerNet差不多,主要讲了下输出gt的格式,公式比较多,结合源码看比较容易懂。
挑几个比较有看点的:
在中心点位置生成和目标大小相同的高斯核,得到heatmap。而CornerNet仅仅在对角生成固定大小的高斯核;
损失函数是针对CenterNet的性质根据FocalLoss改进的像素级惩罚衰减逻辑回归FocalLoss(penalty-reduced pixel-wise logistic regression with focal loss),中文是我瞎翻译的,感觉这么长的名字可以用来当日本轻小说的题目了。
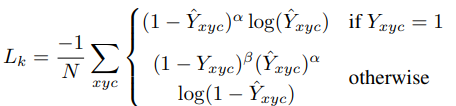
其中的N是预测出的关键点的数量,剩下的都是FocalLoss里的超参数。其实就是像素级的FocalLoss没啥区别。
值得一提的是CenterNet对每个中心点做了偏差预测,为了弥补模型在下采样过程中造成的定位误差。
后面的感觉都半斤八两了,佛系更新。