论文地址:Emotion Recognition From Speech With Recurrent Neural Networks
1 Introduction
在自动语音识别(Automated Speech Recognition, ASR)任务中,语音被模型转化成文字。但是在人们的对话过程中除了文本以外还有其它重要的信息,比如语调、情感、响度。这些信息在语音理解中亦扮演者十分重要的角色。本文将围绕其中“情感”部分进行概述,即语音情感识别(Speech Emotion Recognition, SER)。
在语音情感识别方面存在一些难点:
- 情感是主观的,不同人对于同一段语音,理解出的情感可能不同。
- 同一段语音可能包含多种情感。(可以通过CTC损失函数解决)
- 数据来源:从电影中截取的语音可能和现实中存在偏差。通常会找专业演员来演绎各种情感来制造数据。
2 Related works
大部分文献将语音情感识别视为一个分类问题,对每一个utterance分配一个label。utterance即为一小段语音,是语音的最小单元。
在深度学习之前,大多研究提取底层的手工特征,用传统分类器进行分类,比如HMM(隐马尔可夫模型)或GMM(高斯混合模型)。
深度学习出现后,有人把utterance分帧计算低层特征,用三层全连接层,对输出概率聚合成utterance水平的特征(用简单的统计量,比如最大值,最小值,平均值等),最后用ELM(Extreme Learning Machine)分类。
后面出现了纯深度学习和端到端的架构模型。有人使用Attention CNN,有人用DBN,还有人用迁移学习把语音识别的任务(数据集)迁移到语音情感识别中。
3 Data and preprocessing
IEMOCAP(Interactive Emotional Dyadic Motion Capture)被选作数据集,因为它有详尽的获取方法,免费的学术许可,较长的语音时长和良好的标注。
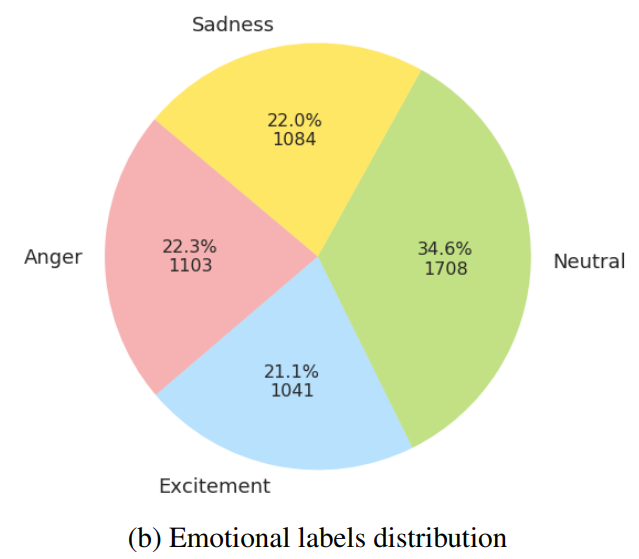
大约包括12个小时,含有视频,音频和人脸关键点的数据。由南加利福尼亚大学戏剧系的10位专业演员表演所得。评估者对每个utterance给出评价(10个情感选项),当一半以上的评估者对某个utterance的评估一致时,该utterance才分配到评估的感情。本文中选取其中4种情感用于分析(生气,兴奋,中立和伤心),只有这些样本才被考虑到本文工作中,下图是标签分布。
原始信号的采样率是16kHz,直接使用计算量很大,需要尽量保持信息的同时减小计算量。本文对utterance进行分帧,帧长为200ms,帧移为100ms,在帧上计算声学特征(用了哪些声学特征见下文介绍),然后把这些特征合在一起作为utterance的特征输入到模型。关于帧长的选取,论文从30ms到200ms都做过实验发现效果差别不大,而较长的帧可以导致比较少的帧,能减小计算量,所以使用了200ms。
对于语音信号的特征主要有三种,一是声学特征,也就是声波的一些属性;二是音律特征,指的是停用词,韵律(押韵,平仄),响度,这个特征依赖于说话人,所以没有用这类特征;三是语义学特征,就是语音对应的文字内容的信息。
本文只使用了声学特征,使用的是python库PyAudioAnalysis的API提供的34个特征,主要包括3个时域特征(过零率,能量,能量熵),5个谱特征,13个MFCC特征,13个音阶特征。也就是一帧的声音用34维的向量来表示。
4 Approach
因为一个utterance只对应一个标签,但是有很多帧,有些帧是不包含情感的,所以输入序列和输出序列难以一一对应,为了应对这个问题,可以使用CTC(Connectionist Temporal Classification)的方法。
CTC模型中的LSTM的输入时间步和输出时间步T为78,因为每个语音样本划分成了78帧。情感标签有4个,加上空白符,得到大小为5的字符集合。真实输出只有一个标签,所以在这些长度为78的输出序列中,经过B转换后能得到一个真实情感标签的那些序列才是我们要的序列,用CTC的方法来使得这些序列产生的概率最大。
注:文本大量参考这篇文章论文笔记:Emotion Recognition From Speech With Recurrent Neural Networks,以自己的语言整理一遍笔记,旨在巩固记忆加深理解,并非完全原创。