1 Abstract
抑郁症一直是全球精神健康疾病的主要原因。重性抑郁症(MDD)是一种常见的心理疾病,严重影响心理和身体健康,甚至可能导致失去生命。由于缺乏诊断抑郁症的有效手段,越来越多的人对通过行为线索来自动诊断以及阶段预测抑郁症感兴趣。摘要提出了一种基于多级注意的多模态抑郁症预测网络,该网络融合了音频、视频和文本模式的特征,同时学习模式内和模式间的相关性。多层次的注意力通过选择每个模式中最具影响力的特征来加强整体学习。我们进行了详尽的实验,为音频、视频和文本模式创建不同的回归模型。建立了几种不同构型的融合模型,分析了各特征和模态的影响。就均方根误差而言,我们比当前基准高出17.52%。
2 Related Works
在[28]中,作者对融合技术在抑郁症检测中的应用进行了综述。他们还提出了一种基于计算语言学的多模态融合检测方法。在[25]中,作者基于上下文感知特征生成技术和端到端可训练的深度神经网络对临床访谈语料库数据集的抑郁水平进行了分析。他们进一步在变压器网络中注入基于主题建模的数据增强技术。Zhang等人发布了一个用于人类行为分析的多模态自发情感语料库[44]。面部表情由3D动态测距、高分辨率视频采集和红外成像传感器捕捉。除了面部环境,还会监测血压、呼吸和脉搏率,以判断一个人的情绪状态。利用AVEC挑战中发布的数据,对音频、视频和生理参数进行调查,以观察受试者情绪状态的关键发现。在[30]中,作者融合了音频、视觉和文本线索来获取多媒体内容中的情感。他们利用特征和决策级融合技术来进行有效的决策。在[2]中,作者利用副语言、头部姿势和眼睛凝视进行多模式抑郁检测。在选定特征的统计检验的帮助下,推理机将受试者分为抑郁和健康两类。当结合多种模式时,了解每种模式在任务预测中的贡献是很重要的,注意力网络可以用来研究其相对重要性。在这篇论文中,我们在每个情态中使用注意来理解情态中低层或深层特征的相对重要性。在融合三种模式的同时,我们还使用了注意力层,并学习了注意力的权重,从而找到每种模式的重要性比例。Querishi等人的论文[32]是唯一一篇在使用数据集子集和在一层应用注意力方面最接近我们的论文。通过在多个层次上使用多层注意力,我们能够获得比它们更好的结果,并且由于注意力操作,网络的计算成本更低,从而最小化了框架的测试时间。
3 Methodology
3.1 Text Modality
由于有几个参与者使用的是英语口语词汇,所以我们对这些词汇进行了修改,用原始的完整词汇替换这些词汇,否则,在训练语言建模或其他预测的神经网络时,这些词汇就会变成不存在于词向量中的词汇。我们使用预训练的通用语句编码器(Universal Sentence Encoder)来得到Embedings。为了获得常数大小的张量,我们使用零补齐短句,并有一个常数数量的时间步为400。每个语句嵌入向量的长度为512,使得最后的数组维数为(400,512)。我们使用两层叠加的双向长短时记忆网络结构,以Embeding为输入,以PHQ分数为输出,训练语音转录的回归模型。每个BLSTM层有200个隐藏单元,其中第一层的前向层的每个隐藏单元的输出连接到第二层的前向隐藏单元的输入。同样的连接也建立在每一个隐藏单元的后向层,以创建堆叠。这两层BLSTM在每一步的输出为(batchsize,400),并将其作为输入发送到前馈层进行回归。我们保持前馈层的节点数为(500,100,60,1),并使用ReLU作为激活函数。
3.2 Audio Modality
对于音频模态,我们使用不同的音频特征(低级特征及其功能)创建模型。在功能(functional)方面,变分的算术平均值和协效率被应用于底层特征,并作为底层特征之上的知识抽象。语音音色是由诸如梅尔频率倒谱系数(MFCC)这样的LLD特征编码的,研究表明,低阶MFCC在情感预测和副语言语音分析任务中更重要。eGeMAPS特征集包含88个特征,包括GeMAPS特征集及其频谱特征和功能。GeMAPS特性包括频率相关特性(音高、抖动、共振峰),能量相关功能(微光,响度,谐波噪声比),光谱参数(α比,哈马伯格比),谐波以及六个时序特征相关的语音比率。除了上述的这些低电平特征外,音频样本的高维深度表示是通过将音频通过深度频谱和VGG网络来提取的。这一特征在本文的其余部分被称为深度densenet特征。
对于音频特征,我们的实验只考虑了参与者所说的向量的跨度。每个特征都是挑战数据的一部分,它们有不同的采样率。功能性音频和深度densenet特征采样频率为1Hz,而BoAW采样频率为10Hz,LLD采样频率为100Hz。低级MFCC特征长度为39,低级eGEMAPS长度为23,总时间步长为140500。而功能的长度分别为78和88,时间步长分别为1300和1410。BoAW-MFCC和BoAW-eGEMAPS的特性长度为100,每个特性的时间步长为14050。深度densenet特征长度为1920维,时间步长为1415步。
在单独的音频通道,我们训练了另一个二层的BLSTM网络,每层有200个隐藏单元。我们将最后一层的输出传递给多层感知器,每一层(500,100,60,1)个节点,并以ReLU作为激活函数。
3.3 Visual Modality
对于挑战数据集中的视频特征,我们对LLD及其function进行了实验。由于深度LSTM网络也可以从数据(如function和更抽象的信息)中学习类似的特征,所以我们选择使用LLD,因为它包含的信息比其平均值和标准差更多。每个用于姿态、注视和面部动作单元(FAU)的LLD特征都以10Hz采样。这些特征的长度分别为6、8、35,都有15000个时间步长。在挑战数据中还提供了BoVW,它的长度为100,有15000个时间步长。我们使用这些特性来训练每个特征的模型,所有特征都使用一个包含200个隐藏单元的BLSTM单层,然后是一个maxpooling和回归器。我们尝试了各种不同的组合,比如所有输出的和、输出的平均值,还使用了maxpooling作为三个备选方案,但是maxpooling效果最好,所以我们在LSTM输出上使用了maxpooling。
3.4 Fusion of Modalities
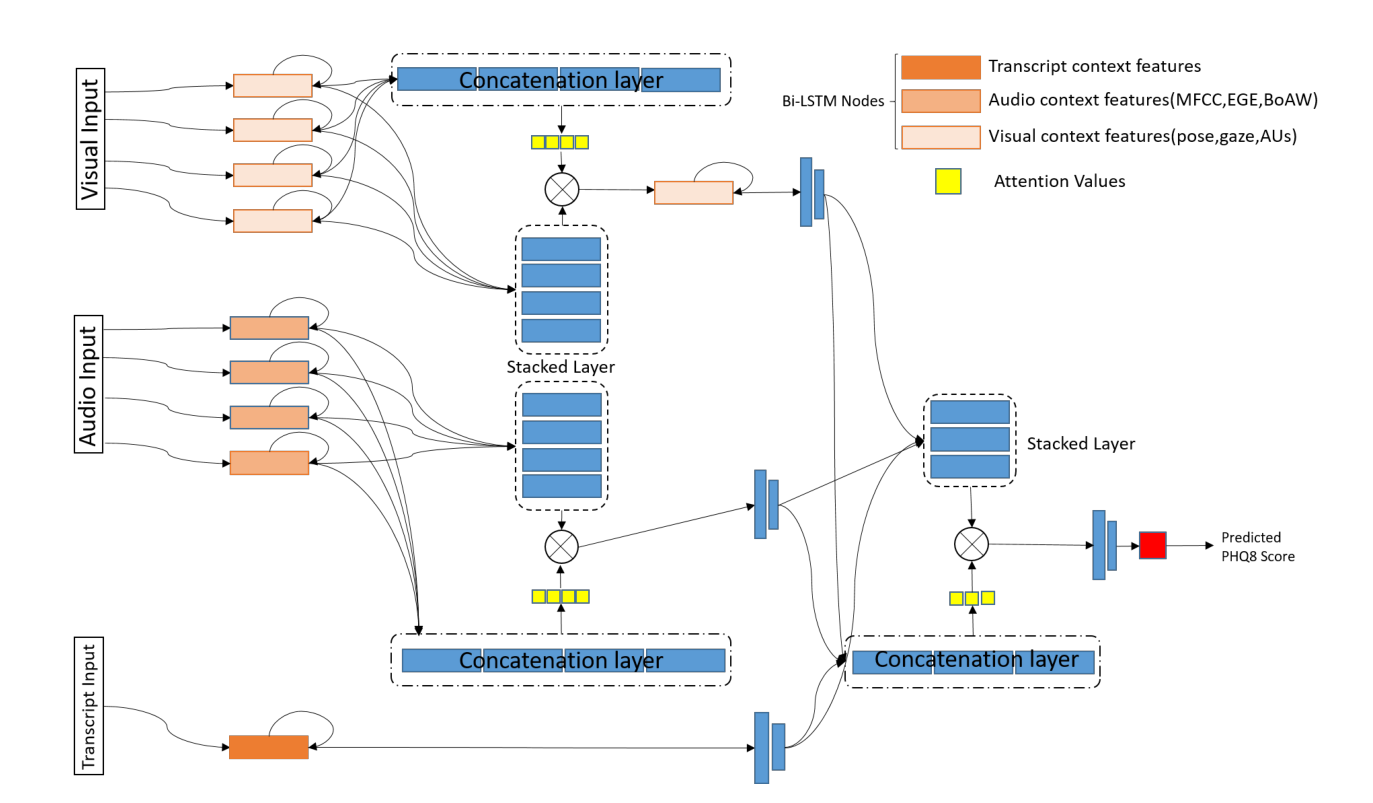
早期融合(early fusion)需要消耗大量的计算资源,当使用神经网络训练时可能导致过拟合,因此,后期融合(late fusion)和混合融合(hybrid fusion)模型变得更加普遍。我们提出了一种基于多级注意力机制的网络,该网络学习每个特征的重要性,并对它们进行相应的加权,从而实现更好的早期融合和预测。这样的注意力网络让我们了解到哪种模态的特征对学习更有影响。它还能表示出各个模态对预测结果准确度所做出的贡献比例。
在融合的过程中,我们在每个通道之间进行了多次实验。首先,我们融合了视频模态的LLD。我们获取注视、姿势和面部动作单元特征,将它们通过包含200个BLSTM神经元的单层网络传递进行前向传播,并对它们施加注意力。注意层的输出通过另一个具有200个单元的BLSTM层。我们对LSTM的输出进行全局最大池化,并通过128个隐藏单元的网络前向传播。(BLSTM->Attention->BLSTM->Maxpooling->FC)
在第二个模型中,我们使用一个类似的网络将视频LLD与BoVWs相结合,该网络由包含200个隐藏单元的BLSTM层、注意力层和另一个BLSTM组成,然后通过一个前馈层进行回归。
第三个融合模型将视频模态的注意向量输出和文本模态的输出进行合并(combine),并在视频回归器之前通过一个堆叠的BLSTM和一个注意力层。
第四个融合模型同时使用音频和文本模态。我们再次在每个模态中获取注意层的输出,并构建一个混合融合网络,但通过两条路径传递它们。在第一种路径中,每个模态的注意力层输出被拼接起来输入注意力层;另一条路径通过两个注意层的输出通过一个堆叠的BLSTM,该BLSTM有2层,每层有200个单元。在堆叠的BLSTM层上应用一个注意层,该输出被馈送到128个隐藏单元的前馈网络。由于使用了文本特征,因此比单独使用音频特征的模型具有更好的性能。
我们的第五个融合模型同时使用视频和文本模态,这里我们再次在视频的每个子模态上使用注意力层,然后使用另一个注意网络将它与文本模态合并。令人惊讶的是,这种融合的结果与音频和文本模态融合非常相似,学习曲线也非常相似。
我们的第六个也是最终融合模型使用了所有的模态。我们使用基于注意力的视觉模态来获得一个包含128个单元的向量,同时使用基于注意力的音频模态来获得一个128单元向量,随后从文本模态中提取信息并从中得到128位(bit)的向量。我们再次在这三种模态上使用另一个注意力层,将它们融合在一起,回归到PHQ8评分。收敛后,视频、音频和文本的注意率分别为[0.21262352, 0.21262285, 0.57475364]。
4 Results
本节详细介绍了所有回归模型的结果及其融合研究。由于测试数据的标签在挑战中不可用,所以我们在验证(dev)分区上展示了大部分结果。测试分区上的唯一结果来自基于文本的模型,我们使用该模型提交了一份报告,并从挑战中获得了所有的分数。
4.1 Results from Text Modality
在E-DAIC(挑战数据)和DAIC-WoZ数据的测试集上,基于注意力的BLSTM网络在文本方面的训练效果优于其他模态。这与临床医生的观察一致,即语言内容是一个重要的标志,具有明确的特征,可能直接影响患者处于哪个抑郁阶段。我们在验证集的根均方误差(RMSE)为4.37 。在测试集上,基于文本的模型能够实现平均绝对误差(MAE)为4.02,RMSE为4.73,对应的一致性相关系数(CCC)为0.67,CCC是该比赛中的主要评估系数。该模型的皮尔逊相关系数(PCC)为0.676,决定系数(r2)为0.457,根据对测试集的挑战结果,斯皮尔曼相关系数(SCC)为0.651。总体而言,该网络工作优于现有模型的8.95%。代码在15个epoch时收敛,验证损失为4.37,批处理大小为10,这些参数是根据经验选择的。预测单个文本抄写的平均测试时间为0.09秒。
4.2 Results from Audio Modality
与基线模型相比,我们每个单独的网络在RMSE方面都表现出色。在基于音频MFCC特征的模型中,我们的表现比基线高出29.80%,而在eGEMAPS中,我们的表现则高出29.04%。对于BoAW-MFCC,我们的表现比基准高出10.44%,而对于BoAW-eGE,我们的表现比基准高出14.46%。每个单独的音频特性代码运行15个epoch,批处理大小为10。使用Functional MFCC对一个样本的平均时间要求为0.23秒,使用Functional eGEMAPS为0.14秒,使用BoAW-MFCC为0.45秒,使用BoAW-eGE为0.45秒,DS-DNet特征为0.13秒。对于音频模型,我们尝试了一个卷积神经网络架构来融合MFCC、eGEMAPS和DS-DNet特性,但是我们发现Bi-LSTMs的性能略好于卷积网络,其对序列特征有着更好的学习能力。
4.3 Results from Visual Modality
视频特征的结果好于基线和技术水平,但仍比文本和语音模式的结果差。在视觉特征中,BoVW的表现最好,超出基线4.8%。与[32]相比,我们使用姿势特征的表现要比他们好9.3%,使用凝视的表现要比他们好6.6%,使用面部动作单元的表现要比他们好8.7%。
4.4 Results from Fused Modalities
该模型使用了所有的特征,融合了多层次的注意力,得到了超出baseline 17.52%的结果。与[32]相比较,音频-文本融合网络和视频-文本融合网络的性能分别提高了5.8%和9.19%,而全融合网络的性能略差。这不是结论性的,因为本文使用的数据集略有不同。注意机制自动权衡每种模式中的每个特征,并允许网络关注回归决策中最重要的特征。这样,网络就能了解特征与PHQ-8 scores之间的关系。
5 Discussion
本文提出了一种基于多级注意力的早期融合网络,融合音频、视频和文本模式来预测抑郁症的严重程度。在这项任务中,我们观察到注意力网络给予文本情态的权重最高,给予音频和视频情态的权重几乎相等。给予特定词更高的权重是与临床医生一致的,因为言语内容对诊断抑郁水平至关重要。音频和视频是同样重要的信息来源,对预防严重程度至关重要。我们对视频数据重要性较低的直觉是,我们可以从视频模态(眼球注视、面部动作单元和头部姿势)中使用有限的特征。临床医生在面对面的访谈中可以观察一个人的身体姿势(自我接触颤抖等)或记录电生理信号,从而进行诊断。
多层次注意力的使用使我们在所有个体和融合模型中获得了比基线和技术水平更好的结果。把注意力放在每个特征和形态上总体上有两方面的优势。首先,这让我们更深入和更好地理解每个特征在抑郁症预测中的重要性。其次,简化了网络的整体计算复杂度,减少了训练和测试时间。实验结果表明,基于多水平注意力的全特征融合模型较基线有17.52%的提高。