1 Abstract
视听情感挑战与工作坊(AVEC 2019)“心智状态、人工智能检测抑郁、跨文化情感识别”是第九届比赛,旨在将多媒体处理和机器学习方法用于自动视听健康和情感分析,所有参与者在相同的条件下严格竞争。该挑战的目标是为多模态信息处理提供一个通用的基准测试集,并将健康和情绪识别社区以及视听处理社区集合在一起,以比较现实生活数据中各种健康和情绪识别方法的相对优点。本文介绍了今年的主要创新点、挑战指南、使用的数据和基线系统在三个拟议任务上的表现:心理状态识别、人工智能抑郁评估和跨文化情感感知。
2 Depression Detection with AI
抑郁症,尤其是重度抑郁症( major depressive disorder, MDD),是一种常见的心理健康问题,对人的思维、感觉和行为方式有负面影响。它会导致各种情绪和身体问题,影响工作和个人生活的许多方面。世界卫生组织(WHO)在2015年宣布抑郁症是全球范围内导致疾病和残疾的主要原因:超过3亿人患有抑郁症。鉴于抑郁症的高患病率及其自杀风险,寻找新的诊断和治疗方法变得越来越重要。由于有令人信服的证据表明抑郁症和相关的精神健康障碍与行为模式的改变有关,人们越来越有兴趣使用自动人类行为分析来基于行为线索(如面部表情和说话韵律)进行计算机辅助抑郁症诊断。面部活动、手势、头部运动和表达能力等行为信号都与抑郁症密切相关。
计算机视觉可以追踪的面部表情和头部动作也是预测抑郁的好方法。据报道,更向下的凝视角度、不那么强烈的微笑、更短的平均微笑持续时间是抑郁症最显著的面部特征。此外,身体表情、手势、头部动作和语言线索也被报道为抑郁检测提供相关线索。综合所有这些证据,有人提议将情感计算技术集成到一个计算机代理中,该代理可以访问人们并识别精神疾病的语言和非语言指标。对创伤后应激障碍患者收集的数据表明,当代理人由充当WoZ的人驱动时,对其抑郁严重程度的自动评估可以实现RMSE小于5;PHQ-8 range∈[0,24] 的cutpoint分别定义为轻度、中度、中度和重度抑郁症。这些结果需要进一步研究,因为代理完全由人工智能驱动,因为向导可能会将虚拟代理驱动到一种情况,从而减轻与抑郁症相关的模式的观察,或者自主代理可能在适当地进行访谈方面存在问题。
3 Distress Analysis Interview Corpus
扩展遇险分析访谈语料库(E-DAIC)是WOZ-DAIC的扩展版本,包含半临床访谈,旨在支持诊断焦虑、抑郁和创伤后应激障碍等心理困扰状况。收集这些访谈是为了创建一个计算机代理来采访人们,并识别精神疾病的语言和非语言指标。收集的数据包括音频和视频记录、使用谷歌云语音识别服务自动转录的文本以及广泛的问卷回答。这些面试是由一个叫做Ellie的动画虚拟面试官进行的。在theWoZ的面试中,虚拟代理由另一个房间的人类面试官(巫师)控制,而在AI的面试中,代理以完全自主的方式使用不同的自动感知和行为生成模块。
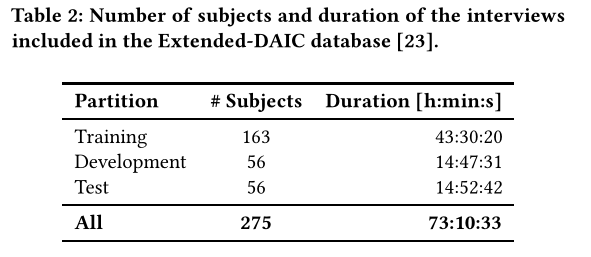
为了达到挑战的目的,E-DAIC数据集被划分为训练、开发和测试集,同时保留了演讲者的整体多样性——在年龄、性别分布和8项患者健康问卷(PHQ8)评分方面——在这些划分内。训练和开发集包括WoZ和人工智能场景的混合,而测试集仅由自主人工智能收集的数据构成。关于扬声器在分区上的分布的详细信息见表2。
4 Baseline Features
视听信号的情感识别通常依赖于特征集,这些特征集的提取基于近几十年来在视听信号处理领域的研究出来的特定技术,在语音方面有:梅尔倒频谱系数(Mel Frequency Cepstral Coefficients, MFCCs);视觉方面则有:面部活动单元(Facial Action Units, FAUs)。
4.1 Expert-knowledge
影响感知的传统方法是在固定时间内,通过一组滑动窗口计算的统计度量,来总结随时间变化的视听信号低水平描述符(low-level descriptors, LLDs)。
在音频方面,我们计算了扩展GeMAPs特征集(extended Geneva Minimalistic Acoustic Parameter Set, eGeMAPS),它包含88个覆盖上述声学维度,并在这里用作基线。除此之外,我们使用OpenSMILE工具包使MFCCs 1-13 的一阶和二阶差分被计算为一组声学LLDs。在视觉方面,我们使用openFace工具包提取每个视频帧的17个FAU强度,以及一个置信度。此外,还提取了姿态(pose)和凝视(gaze)的描述符。
4.2 Bags-of-Words
词袋(bags-of-words, BoW)技术起源于文本处理,它代表了LLD的分布。我们使用MFCCs和eGeMAPs特征集作为声学数据,FAU的强度作为视频数据。MFCCs和eGeMAPS的LLD是经过标准化处理的。
为了生成BoW表示,声学和视觉特征都在长度为4s的音视频段上进行处理,对于SEWA数据集的每一段为100ms,对于USoM和E-DAIC数据集为1s。随机采样示例来构建字典,并从结果项频率中取对数以压缩它们的范围。整个跨模式BoW(XBoW)处理链是使用开源工具包openXBOW执行的。
4.3 Deep Representations
在去年的挑战中,我们将深度频谱特征(Deep Spectrum features)作为一种基于深度学习的音频基线特征表示。深度频谱特征的灵感来自于图像处理中常见的深度表示学习范式:将语音实例的频谱图像输入到预训练好的CNNs中,提取一组由此产生的激活值作为特征向量。
在今年的挑战中,我们使用VGG-16、AlexNet、DenseNet-121和DenseNet-201四个鲁棒的预训练模型中提取了深度频谱特征;在AVEC 2019 CES上使用AlexNet纯粹是为了与之前的AVEC 2018 CES保持一致。语音文件首先被转换成具有128个mel频段的mel谱图图像,所有挑战语料库的窗口宽度为4s, USoM和E-DAIC数据集的跳数为1s, SEWA数据集的跳数为100ms。随后,基于频谱的图像通过预先训练的网络进行转发。然后,通过激活VGG-16和AlexNet中的第二个全连接层形成4096维的特征向量,通过激活DenseNet-121和DenseNet-201网络的最后一个平均池化层分别得到1024和1920维的特征向量。
我们还提供了两个基线深度视觉表示,分别使用了VGG-16网络和ResNet-50网络,这两个网络都是使用Affwild数据集进行预训练的。首先应用openFace工具包来检测脸部区域,然后执行面部对齐。然后,我们冻结两个预先训练的模型的权重,并分别将对齐的脸部图像输入两个CNN。为了获得每个帧的深度表示,我们分别从预训练的VGG-16网络中提取第一个全连接层的输出,从预训练的ResNet-50网络中提取全局平均池化层的输出。因此,每一帧都提供了来自VGG的4096维深特征向量和来自ResNet的2048维深特征向量。
5 Baseline System
对于抑郁检测基线,我们使用单层64-d GRU作为我们的递归网络,其失步正规化率为20%,然后使用64-d全连通层获得单值回归评分。为了处理偏差,我们将PHQ-8分数标签转换为浮点数,方法是在培训之前按25的倍数缩小比例。使用CCC损失函数和评价分数对网络进行训练和评价,使用原始的PHQ量表报告RMSE结果。批处理大小为15的方法得到了一致的使用,并且在不同的特性集之间优化了学习率。为了使数据适合GPU内存,为会话分配了最大的序列长度。对于MFCCs和eGeMAPS LLDs,以及诸如DeepSpectrum、ResNet和VGG等高维深表示,使用的最大序列长度为20分钟。另外,对于ResNet、VGG和深度光谱表示帧,根据维数的不同,将保留两帧中的一帧或四帧中的一帧,以便将数据加载到内存中。融合不同的视听表现是通过平均他们的分数来实现的。
DDS的基线结果见表6。结果表明,在开发集上,利用深度谱(DS-VGG)特征获取音频特征的最佳CCC评分,利用ResNet特征获取视觉特征的最佳CCC评分。这些结果表明表达的力量深层神经网络学习的大量数据时在不同的上下文中使用他们最初的设计,这是证实与ResNet视觉模型在测试集上实现最好的结果,尽管相对较低的CCC。
不同表现形式的融合在开发集上获得了最好的结果,测试集上返回的RMSE比使用AVEC 2017基线系统在DAIC-WoZ数据集上获得的RMSE稍好一些;AVEC2019年的RMSE=6.37,而AVEC 2017年的RMSE=6.97。然而,为今年的挑战开发的基线系统更加复杂,与今年的GRU-RNNs相比,它是一个简单的线性回归模型,因此,根据2017年AVEC抑郁亚挑战的最佳结果(RMSE=4.99),应该最好地考虑相应的分数。
根据从与虚拟代理的交互中获得的抑郁程度自动感知的结果,当代理仅由人工智能驱动时,识别似乎比由人作为WoZ驱动时更具挑战性。这一观察结果为设计抑郁症诱因的设计带来了有趣的研究问题。通过强化学习,根据agent的交互方式。