DeepLabv1
论文地址:Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
其实挺烦看这种远古论文的,引用的算法现在都不太常见,使用的措辞也和现在不太一样。该论文主要引入了空洞卷积(Astrous/Dilated Convolution)和条件随机场(Conditional Random Field, CRF)。
空洞卷积,顾名思义,即是在卷积核权重之间注入空洞,使用小卷积核的计算量获得大卷积核的感受野。(如理解有误请邮件指正)
空洞卷积比传统卷积多一个参数为采样率(dilation rate),表示一个卷积核中采样的间隔。

条件随机场涉及到很多机器学习的知识,学起来比较耗时间,而且在后来的DeepLab版本中被取代,所以此处暂略,有机会再补上。
DeepLabv2
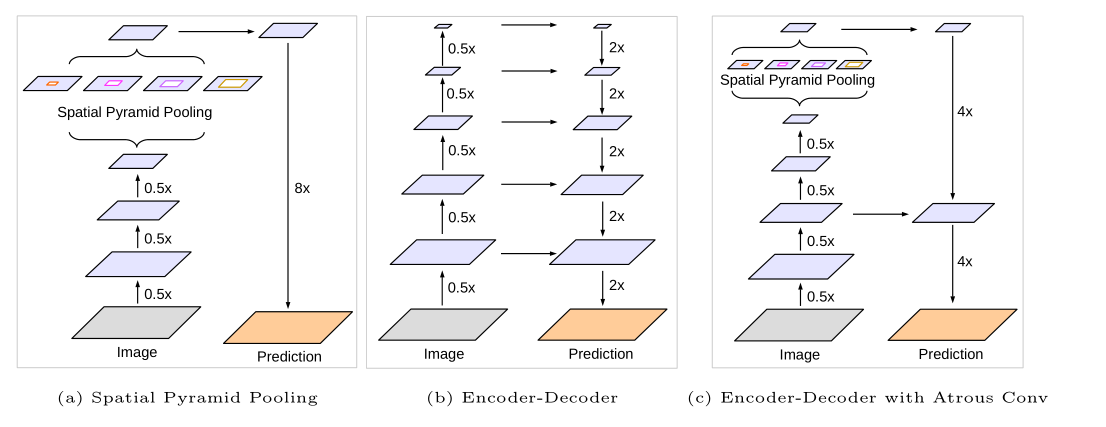
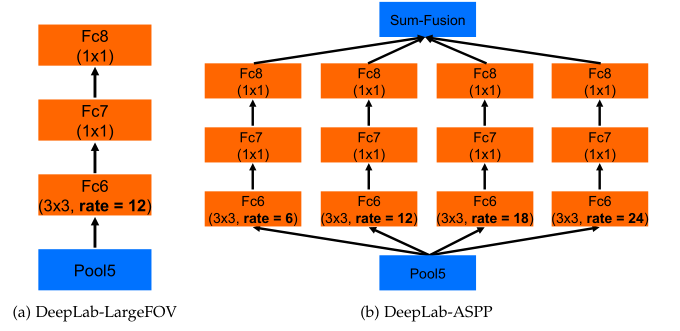
比起v1,v2的主要改动是增加了带孔空间金字塔池化(ASPP)模块,其思想来源于SPPnet。但是文中对ASPP的阐述非常少,完全没有讲清楚ASPP的机制,只能通过论文中的图片和网上的博客来猜。
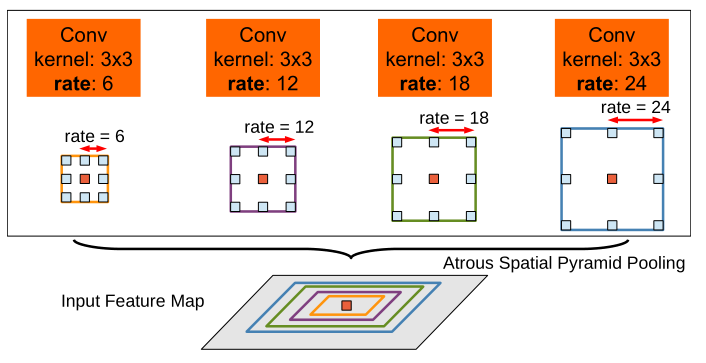
可以看出,ASPP使用了几种不同采样率的空洞卷积,对一张特征图得出多个分支后,最终concat到一起。可以借助代码理解一下这部分:
1 | #without bn version |
DeepLabv3
论文地址:Rethinking Atrous Convolution for Semantic Image Segmentation
提出了串联(cascade)和并联(parallel)两种格式,并指出并联效果更好。

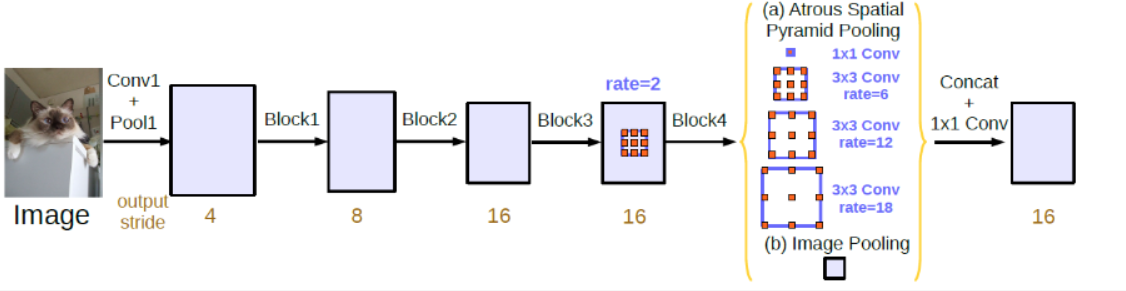
网络去除了CRF,修改了一些参数,应用了一些新技术(比如批归一化)使模型更加精简。
虽然从文中看不出做了多少修改,但作者说性能得到了很大的提升。科科。
DeepLabv3+
论文地址:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
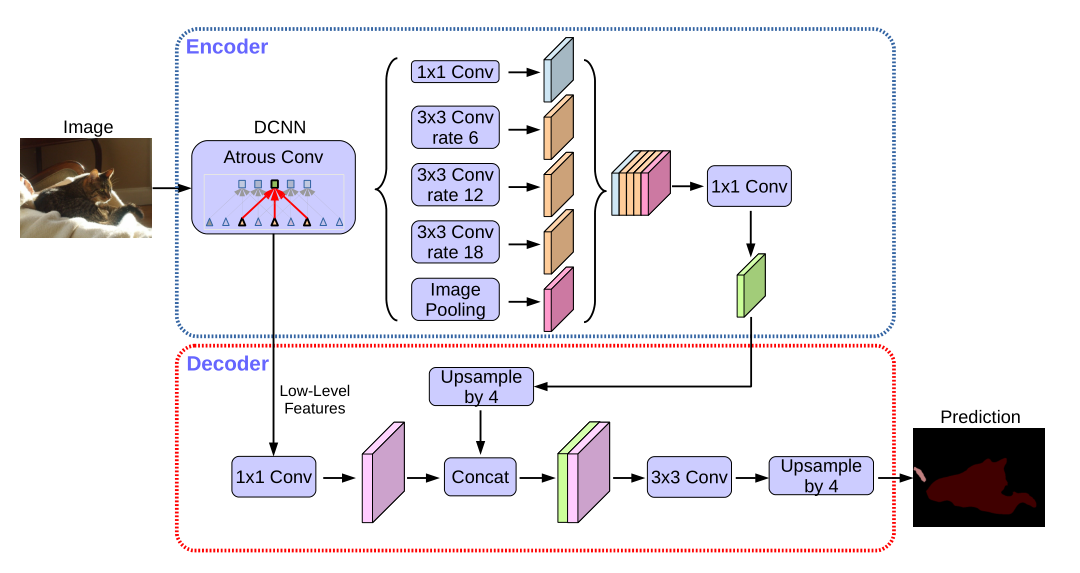
8102年,deeplab终于将Encoder-Decoder结构加进网络里了,之前一直用的双线性插值做上采样。