YOLOv1
论文地址:You Only Look Once: Unified, Real-Time Object Detection
摘要
众所周知,在深度学习目标检测领域有着两个流派,分别是基于候选区域的R-CNN流派和直接回归输出边框的YOLO流派。R-CNN系列的准确率较高,但即便发展到Faster R-CNN,运算速度也才只有7fps。为了使检测工作更接近实时,作者提出了YOLO结构。

YOLO 的实现
(第一次看可能有点复杂,建议拿笔出来边梳理边看)
YOLO 将输入图像划分为 S × S 个网格。如果一个物体的中心点在这个网格中,则该网格负责检测这个物体。每个网格预测 B 个边框(bounding box)及其置信度(confidence)。其中置信度为该网格包含目标物体的概率乘以预测边界框与真实边界框(ground truth)的交并比(IOU),即:
也就是说,当置信度为0时,边框内不含有任何目标物,除此之外置信度都等于交并比。该置信度只是个预测值,受真实的置信度监督。这点可以从后面的损失函数看出来。
于是我们得知,每个边框由5个预测值组成,分别为$x,y,w,h,confidence$。
同时每个网格预测一组 C 个类别的概率 $Pr(Class_i|Object)$,即输出一组长度为 C 的概率向量。这个概率表示网格含有物体的情况下,各个类别属于该网格的概率。
经过上述步骤,最终在神经网络末端输出一个$S×S×(B×5+C)$的张量。

测试时,将置信度和每一类概率相乘
得到的Score表示每一类在每个边框中的置信度(class-specific confidence for each box)。通过设置阈值筛选出得分高的box,再以的分最高的box为基准进行NMS选出最优结果。
网络结构
如图,在 PASCAL VOC 数据集中,图像输入为 448×448,取 S=7,B=2,一共有20 个类别(C=20),则输出就是 7x7x30 的一个 tensor。

可以看出这是一个彻头彻尾的端到端网络。看到这里可能会有点震惊,上面讲了那么多复杂的设定到头来居然只是个这么朴素的端到端网络?事实上,上面那么多设定大多都是来源于其巧妙设计的损失函数。
损失函数

由于坐标、长宽、置信度的重要性不同,作者给予了他们不同的损失函数和权重。
- 重视坐标预测,给这些损失前面赋予更大的权重,取 5。
- 对没有 object 的 box 的 confidence loss,赋予较小的损失权重,取 0.5。
- 有 object 的 box 的 confidence loss 和类别的 loss 的损失权重取 1。
- 对不同大小的边框预测中,相比于大边框,小边框预测偏一点造成的影响更大。而均方误差中对同样的偏移 loss 是一样。为了缓和这个问题,作者用了一个比较取巧的办法,就是将 box 的 width 和 height 取平方根代替原本的 height 和 width。
YOLO 的缺点
- YOLO对比较密集的、小型的物体(如鸟群)检测效果不佳。因为会有两个同类物体出现在同一个网格中的情况。
- 同一类物体出现的新的不常见的长宽比和其他情况时,泛化能力偏弱。
- 由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上,还有待加强。
- 召回率远低于RCNN系列。
YOLOv2 & YOLO9000
论文地址:YOLO9000: Better, Faster, Stronger
概述
- YOLOv2:在多方面进行改进,在mAP上超过了使用resnet作为backbone的Faster R-CNN 和 SSD,而且速度更快。
- YOLO9000:使用大量分类数据集和检测数据集进行联合训练,能够对9000+类别进行检测。
Better
YOLOv2 和 YOLOv1 对比:

- 增加了 batch norm。
- 使用高分辨率微调模型:YOLOv1 采用224×224大小的图片进行预训练,但训练检测模型时使用的是448×448,这一变动对模型性能会产生一定影响。而YOLOv2在常规预训练和进行正式训练之间使用了448×448的分类图像样本进行了微调,缓解了分辨率突然切换造成的影响。
- 采用了 Anchor Boxes:借鉴Faster R-CNN的做法使用了锚框,大幅提高了召回率但mAP轻微下降。
- 将图片输入尺寸改为416×416,grid改为13×13,使grid长宽为奇数,这样能更有效地预测图片中央的目标物(根据经验,目标物在图片中央的可能性较大)。
- 使用 k-means 聚类算法来选择锚框:手工选择的锚框可能对性能产生影响性能。作者使用k-means对训练集目标框进行聚类,以IOU为距离计算指标,即 $d = 1 - IOU$。在对性能和准确率进行衡量之后,选择了 $k = 5$,得出聚类结果的5个聚类中心作为锚框的最终选择(只取锚框的大小和形状,不取锚框的位置)。
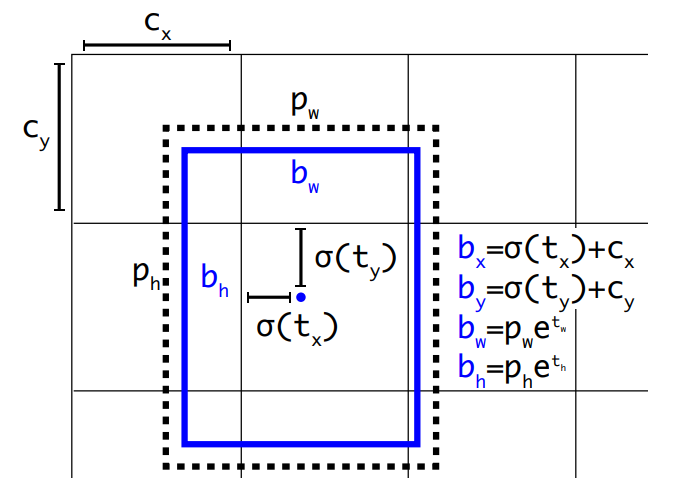
- Direct location prediction:在RPN中的锚框非常不稳定,其公式如下:
$t_x$和$t_y$为预测值,当$t_x=1$时,预测框相比于原本的锚框将右移一整个锚框的宽度!YOLOv2对这种方法进行了改进:
$t_x,t_y,t_w,t_h,t_o$为预测值,被Sigmoid函数限制在(0,1)之间。之后再通过下图的一些运算得到最终box。在限制了预测值大小的情况下,模型参数会更容易学习。
- 多尺度训练:因为YOLOv2是全卷积,所以能用任意大小的图像作为输入。作者使用了{320,352,…,608}大小的图像进行训练以提高模型的泛化性能。
Faster
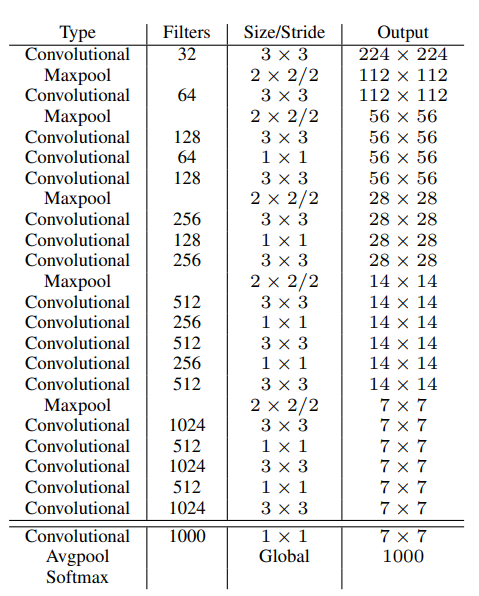
大部分网络使用VGG16作为backbone,但是VGG有点臃肿。作者自定义了Darknet-19作为网络的backbone。
Stronger
这部分讲了下YOLO9000和WordTree,但没有看懂而且好像不是很重要的亚子,跳了。
YOLOv3
论文地址:YOLOv3: An Incremental Improvement
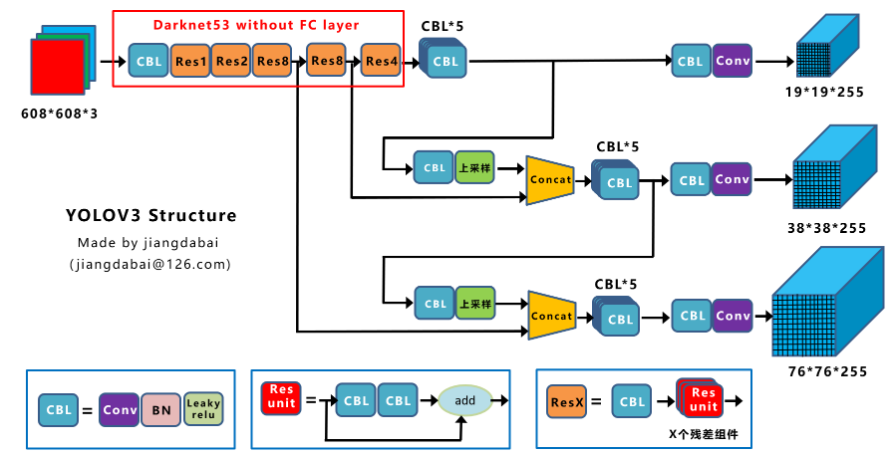
相比于YOLOv2,YOLOv3主要修改了网络结构:
- 学习Encoder-Decoder结构加上了上采样和特征融合;
- 在网络的不同地方产生了3个不同尺寸的output。
参考文献
[1]YOLOv1论文翻译
[2]从YOLOv1到YOLOv3,目标检测的进化之路
[3]YOLOv2 / YOLO9000 深入理解
[4]Yolo系列其二:Yolo_v2
[5]深入浅出Yolo系列之Yolov3&Yolov4&Yolov5核心基础知识完整讲解
[6]Mish:一个新的state of the art的激活函数,ReLU的继任者