FCN
论文地址:Fully Convolutional Networks for Semantic Segmentation
概述
原始的 CNN 在图像的分类和定位任务中都获得了不错的成绩,但在分割任务中表现不佳。本文提出了一种全卷积网络(Fully Convolution Network, FCN),通过进行像素级的预测(pixelwise prediction)来实现语义分割(semantic segmentaion)。

实现全卷积网络主要基于三种技术:
- 全卷积化(Fully Convolutional)
- 反卷积(Deconvolution)
- 跃层结构(Skip Layer)
全卷积化

简单来说就是把传统CNN最后的全连接层换成了卷积层。全卷积在多篇目标检测的论文中都有提到,其能提取出样本的特征图,样本目标区域对应特征图的感兴趣区域所在位置(如上图中的猫对应heatmap中的彩色像素)。
上采样(Upsampling)

图像(图a)在经过卷积、池化等一系列处理后,得到的特征图(图b)分辨率远小于原图像。这样一来特征图中的像素无法与原图中一一对应,无法对每个像素进行预测。于是需要对特征图进行上采样以提高特征图的分辨率。文中对比了三种上采样的方法,最终选择了反卷积。
Deconvolution
反卷积是文章作者最终采用的方法,下面是两种反卷积的示例,图解起来十分直观:


下面是另一种解释,这样一看好像确实是把卷积的操作反过来了:

跃层结构(Skip Layer)
FCN 通过卷积和反卷积我们基本能定位到目标区域,但是,我们会发现模型前期是通过卷积、池化、非线性激活函数等作用输出了特征权重图像,我们经过反卷积等操作输出的图像实际是很粗糙的,毕竟丢了很多细节。因此我们需要找到一种方式填补丢失的细节数据,所以就有了跃层结构。
跃层结构将浅层的位置信息和深层的语义信息结合起来,得到更佳鲁棒的结果,其过程如图:

网络结构

训练过程
训练过程分为四个阶段,也体现了作者的设计思路,值得研究。
第一阶段

使用数据集对模型的分类backbone进行预训练,使卷积层获得提取相应特征的能力。最后两层红色的是全连接层。
第二阶段

从特征小图(16×16×4096)预测分割小图(16×16×21),之后直接升采样为大图(300×300×21)。这里输出通道数为21的原因是:采用的PASCAL数据集中有20类,算上背景类一共21类。每个通道预测一类的像素。反卷积(橙色)的步长为32,故该网络被称为FCN-32s。
第三阶段

这个阶段上采样分为两次完成(橙色×2)。 在第二次升采样前,把第4个pooling层(绿色)的预测结果(蓝色)通过跃层结构融合进来,提升精确性。 第二次反卷积步长为16,这个网络称为FCN-16s。
第四阶段

这个阶段和第三阶段差不多,相较多了一次上采样。这大概是最终得出的FCN模型,因为同样的原因被称为FCN-8s。
比较这几个阶段的输出可以看出,跃层结构利用浅层信息辅助逐步升采样,有更精细的结果。

FCN 的缺点
- 分割的结果不够精细。图像过于模糊或平滑,没有分割出目标图像的细节。
- 因为模型是基于CNN改进而来,即便是用卷积替换了全连接,但是依然是独立像素进行分类,没有充分考虑像素与像素之间的关系。
U-Net
论文地址:U-Net: Convolutional Networks for Biomedical Image Segmentation
U-Net是医学图像领域十分常用的一种分割网络,因为跟FCN十分相似,就放这里顺便讲了。
网络结构

由于整个结构图呈”U”字型,故名”U-Net”。在知道FCN的原理后,从图中可以很明显地看出U-Net的结构和FCN没太大区别。其主要区别于以下几点:
由于Unet的主要目标数据集为医学影像(最开始是细胞图像),只需要对每个像素点进行二值分割(有病/没病),故输出的特征图只有2个channel。(output segmentation: 388×388×2)
在上采样部分依然有大量的特征通道,使得网络可以将环境信息向更高的分辨率层传播。下采样和上采样部分几乎是对称的。
输入图像尺寸(572×572)和输出图像尺寸(388×388)不一样。这点似乎是为了配合一种名为overlap-tile的方法。如下图,使用左图蓝色区域预测右图黄色区域,滑动蓝色区域重复此操作直到预测完整张图片(这种细胞图尺寸通常都很大)。最终会导致最边上的蓝色区域没法预测,对于这部分使用镜像法(mirroring)外推。
注:关于这部分我也不太确定,想要了解详细原理可以去官网看原版的实现代码。

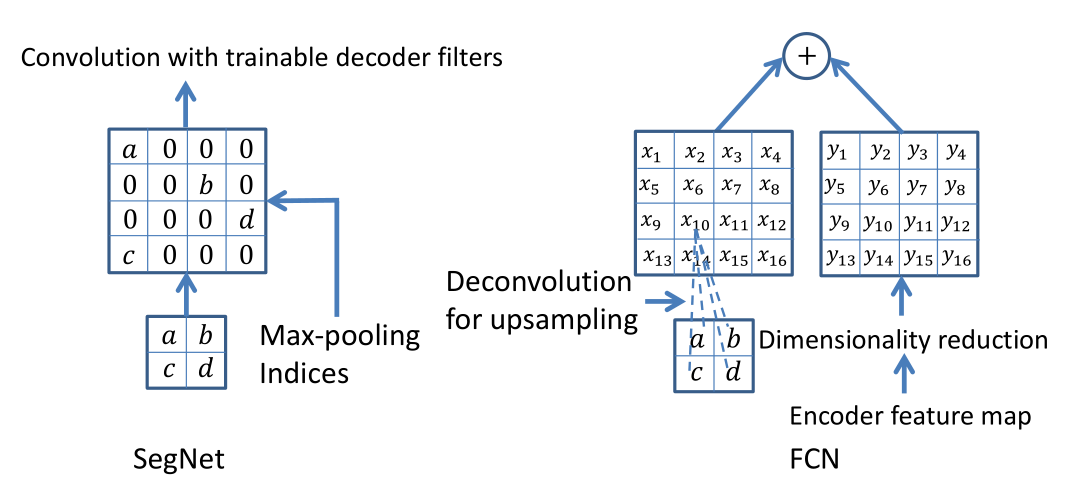
浅层特征和深层特征合并时,Unet使用的是拼接方法(图中白色模块,估计是为了保留更多的channel),而FCN使用的是求和。
用少量图像训练便能取得不错的效果,这点对医学领域图像数据集较少的特性十分友好。
SegNet
论文地址:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
说实话这篇文章没啥意思,就概括地科普一下吧。
首先架构还是和FCN一样,没啥变化,但文中将网络前面提取特征的部分称为编码器(Encoder),后面上采样的部分称为解码器(Decoder)。这组词被沿用至今,可能就是在这里提出来的。
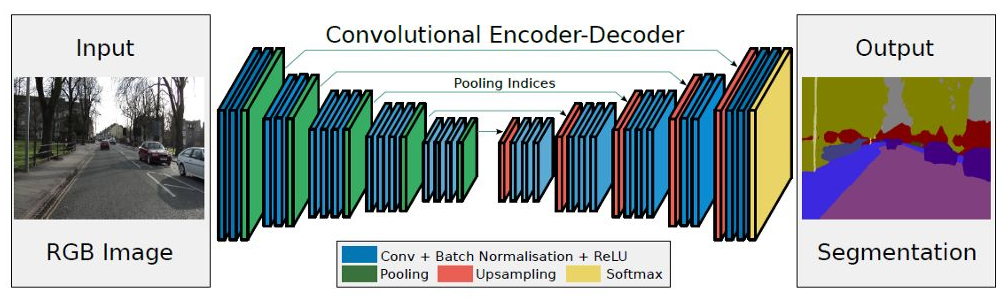
然后整篇文章的亮点在于:解码器通过使用从相应的编码器接受的max-pooling索引来进行非线性上采样。这种方法减少了所需要训练的参数量,并且改善了边界划分效果。
参考文献
[1]卷积神经网络CNN(1)——图像卷积与反卷积(后卷积,转置卷积)
[2]【论文笔记】FCN
[3]10分钟看懂全卷积神经网络( FCN ):语义分割深度模型先驱
[4]FCN的学习及理解(Fully Convolutional Networks for Semantic Segmentation)
[5]FCN的理解
[6]FCN和U-Net
[7]U-net翻译
[8]U-net论文解析